如何构建基于 Redis 的 RAG 系统、如何意图识别?
#2025/12/23 #ai
RAG 系统(Retrieval-Augmented Generation)通过结合 “私有数据检索” 与 “大模型生成能力”
- 让 AI 能够基于特定文档回答问题,而无需重新训练模型。
- 并且减少 AI
幻觉
目录
整体流程
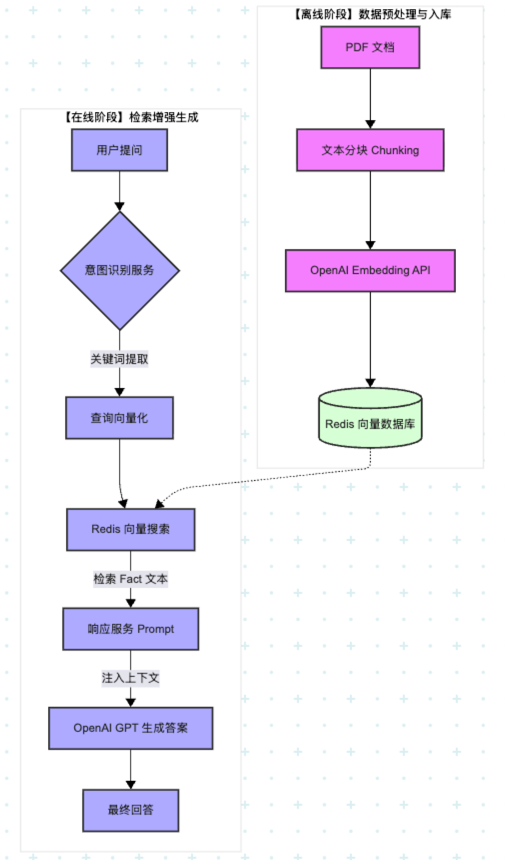
1. 核心数据流转表
| 步骤 | 输入 | 输出 | 处理组件 |
|---|---|---|---|
| 1. 提取 | PDF 文档 | 文本块 (Chunks) | DataService |
| 2. 转化 | 文本块 | 向量 (Vectors) | OpenAI Embedding API |
| 3. 路由 | 用户问题 | 核心关键词 (Intent) | IntentService (GPT-3.5) |
| 4. 匹配 | 关键词向量 | 相关事实片段 (Facts) | Redis Vector Search |
| 5. 渲染 | 事实 + 问题 | 最终答案 | ResponseService (GPT-3.5) |
2. 核心组件设计
系统由三个主要服务组成,各司其职:
| 组件名称 | 核心职责 |
|---|---|
| 意图识别 (Intent) | 判断用户是闲聊还是查数据; 提取关键词; 识别查询哪个数据源。 |
| 信息检索 (Retrieval) | 将用户问题转化为向量,在 Redis 向量数据库中匹配最相关的知识块。 |
| 响应生成 (Response) | 将检索到的“事实内容”连同“用户问题”一起交给 LLM,生成最终答案。 |
3. 核心服务实现
3.1. 🛠️ 数据服务 (DataService):向量化与存储
该服务负责将 PDF 文档转化为机器可理解的向量,并存入 Redis。
- PDF 分块:将长文档切分为固定长度(如 1000 字符)的文本块。
- 向量化:调用 OpenAI
text-embedding-ada-002接口生成嵌入向量。 - 向量存储:利用 Redis 的
HSET存储文本及其对应的向量。
class DataService:
def __init__(self):
self.redis_client = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
def pdf_to_embeddings(self, pdf_path: str, chunk_length: int = 1000):
"""将 PDF 转换为嵌入向量列表"""
reader = PdfReader(pdf_path)
chunks = []
# 文本分块逻辑
for page in reader.pages:
text = page.extract_text()
chunks.extend([text[i:i+chunk_length] for i in range(0, len(text), chunk_length)])
# 获取嵌入向量
response = openai.Embedding.create(model='text-embedding-ada-002', input=chunks)
return [{'id': i, 'vector': v['embedding'], 'text': chunks[i]}
for i, v in enumerate(response["data"])]
def load_data_to_redis(self, embeddings):
"""将向量数据持久化到 Redis"""
for item in embeddings:
key = f"doc:{item['id']}"
# 将向量转换为二进制格式以供 Redis 搜索
item["vector"] = np.array(item["vector"], dtype=np.float32).tobytes()
self.redis_client.hset(key, mapping=item)
💡 提示: 虽然 Redis 很方便,但在处理大规模向量搜索时,原生的向量数据库(如 Pinecone 或 Weaviate)可能会提供更专业的性能支持。
3.2. 🔍 意图识别 (IntentService):理解用户
意图识别不直接回答问题,而是从问题中提取关键词,提高检索精度。
class IntentService:
def get_intent(self, user_question: str):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{
"role": "user",
"content": f"从以下问题中提取关键词,只返回关键词: {user_question}"
}]
)
return response.choices[0].message.content
3.3. ✍️ 响应服务 (ResponseService):生成回答
这是最后一步,将检索到的“事实”作为上下文喂给模型。
class ResponseService:
def generate_response(self, facts, user_question):
response = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{
"role": "user",
"content": f"基于以下事实(FACTS)回答问题(QUESTION)。\nFACTS: {facts}\nQUESTION: {user_question}"
}]
)
return response.choices[0].message.content
4. 完整业务流程
当用户提问 “在哪里可以找到宝箱?” 时,系统内部的操作顺序如下:
- 初始化:数据服务加载 PDF,生成向量并存入 Redis。
- 提取意图:
IntentService分析问题,提取出关键词(如:“宝箱、位置”)。 - 检索事实:
DataService根据关键词向量,在 Redis 中搜索出最相关的文档片段(Facts)。 - 生成答案:
ResponseService整合事实和问题,产出最终的人类可读答案。
4.1. 💡 进阶优化建议
- 分块策略:不要只按字数分块,尝试按“段落”或“语义”分块,能显著提升回复质量。
- 上下文关联:在 Redis 中存储数据时,可以将“标题”作为元数据一起存储,为模型提供更丰富的背景。
- 框架选择:对于更复杂的项目,建议探索 LangChain 或 LlamaIndex,它们提供了更成熟的 RAG 工具链。
5. 意图识别(Intent Recognition)
将用户问题“识别”出来的过程,本质上是将非结构化的自然语言转化为结构化的指令或分类。主要通过以下几种路径实现:
5.1. 基于 LLM 的“语义提取”(最流行的方法)
你提供的代码就是这种方式。它利用大语言模型(如 GPT-3.5)强大的理解能力,通过 Prompt(提示词) 直接告诉模型该做什么。
- 原理:模型不只是在做
关键词匹配,而是在理解“语境”。 - 实现过程:
- 输入:用户原始问题(例如:“这个产品的保修期是多久?”)。
- 指令:给模型一段 Prompt:
- “判断以下问题的意图。如果是关于
产品的,返回 ‘PRODUCT’;如果是闲聊,返回 ‘CHAT’。”
- “判断以下问题的意图。如果是关于
- 推理:
- 模型根据训练数据中的语义关联,识别出 “
保修期” 属于“PRODUCT”范畴。
- 模型根据训练数据中的语义关联,识别出 “
- 输出:
- 得到结构化的标签。
5.2. 基于“嵌入向量”的相似度匹配 (Vector Similarity)
这是一种更数学化的方式,不需要模型实时“思考”,而是靠“比对”。
- 原理:将用户的问题转化为一串数字(
Embedding Vector),然后看这串数字在空间中离哪个已知意图最近。 - 实现过程:
- 预设意图:
- 你提前准备好几个
标准意图的向量,比如“退货流程”、“技术支持”。
- 你提前准备好几个
- 向量化:
- 用户问“我不想要这个东西了”,系统将其转化为向量。
- 计算距离:
- 系统计算发现,“我不想要了”的向量与“退货流程”的向量距离最近(
余弦相似度最高)。
- 系统计算发现,“我不想要了”的向量与“退货流程”的向量距离最近(
- 判定:
- 命中“退货流程”意图。
- 预设意图:
5.3. 多级过滤与路由 (Routing)
在复杂系统中,意图识别通常是一个漏斗模型:
- 第一层:安全合规过滤
- 识别是否有恶意代码注入、敏感政治话题或谩骂。如果是,直接拦截。
- 第二层:领域分类 (Domain Classification)
- 判断是去“业务数据库”查资料(RAG),还是调用“外部工具”(如查询天气),或者是纯粹的“闲聊”。
- 第三层:关键词/实体提取 (Entity Extraction)
- 正如你代码中写的
get_intent函数,它从问题中抠出“关键词”。比如“北京明天的天气”,意图是“查天气”,实体是“北京”和“明天”。
- 正如你代码中写的
5.4. 为什么你代码中的 IntentService 很重要?
在 RAG(检索增强生成)系统中,意图识别起到了“导航员”**的作用:
- 节省成本:如果用户只是说“你好”,意图识别发现是闲聊,就不会去触发昂贵的向量数据库搜索(DataService),直接让 LLM 回复即可。
- 提高精度:用户的问题往往很长且模糊。通过意图服务提取出“关键词”后再去 Redis 搜索,比直接拿整个句子去搜索匹配度更高。
5.4.1. 举个例子:
用户问:“那个...我昨天买的那个蓝色的杯子,我怎么才能把它退了啊?”
意图识别后:
- 意图 = 退货;
- 关键词 = 杯子、退货方法。
结果: 系统直接去库里搜“退货政策”,而不是去搜“蓝色的杯子”。