大模型是如何训练的?
#AI #chatGPT #agi #大模型
目录
1. 先看看大模型自己的回答 (sonnet)
大模型的训练是一个复杂而资源密集的过程。以下是大模型训练的主要步骤和关键点:
- 数据准备
- 收集海量高质量文本数据,通常是数百GB到TB级别
- 对数据进行清洗、标准化和预处理
- 构建词表,将文本转换为模型可处理的数字序列
- 模型设计
- 选择合适的模型架构,如Transformer
- 确定模型规模,包括层数、隐藏单元数等超参数
- 设计训练目标,如语言模型、掩码语言模型等
- 分布式训练
- 使用大规模GPU/TPU集群进行并行训练
- 采用数据并行、模型并行等技术提高训练效率
- 使用混合精度训练、梯度累积等方法节省显存
- 优化策略
- 选择合适的优化器,如Adam
- 设计学习率调度策略
- 使用梯度裁剪等技术稳定训练
- 训练过程
- 迭代训练数百万到数十亿步
- 监控损失、困惑度等指标
- 定期保存检查点,以便恢复训练
- 评估与改进
- 在验证集上评估模型性能
- 分析模型输出,找出不足之处
- 调整超参数、数据或模型结构进行优化
- 部署与应用
- 模型压缩和量化
- 部署到推理服务器
- 针对下游任务进行微调
整个过程需要大量的计算资源、专业知识和反复实验。训练一个大规模语言模型可能需要
- 数周到数月的时间
- 成本可达数百万美元。
2. 为什么要花这么大的成本训练?
因为:

3. 先在单机上训练?

这得多好单机性能,完全搞不定啊
4. 多机器训练
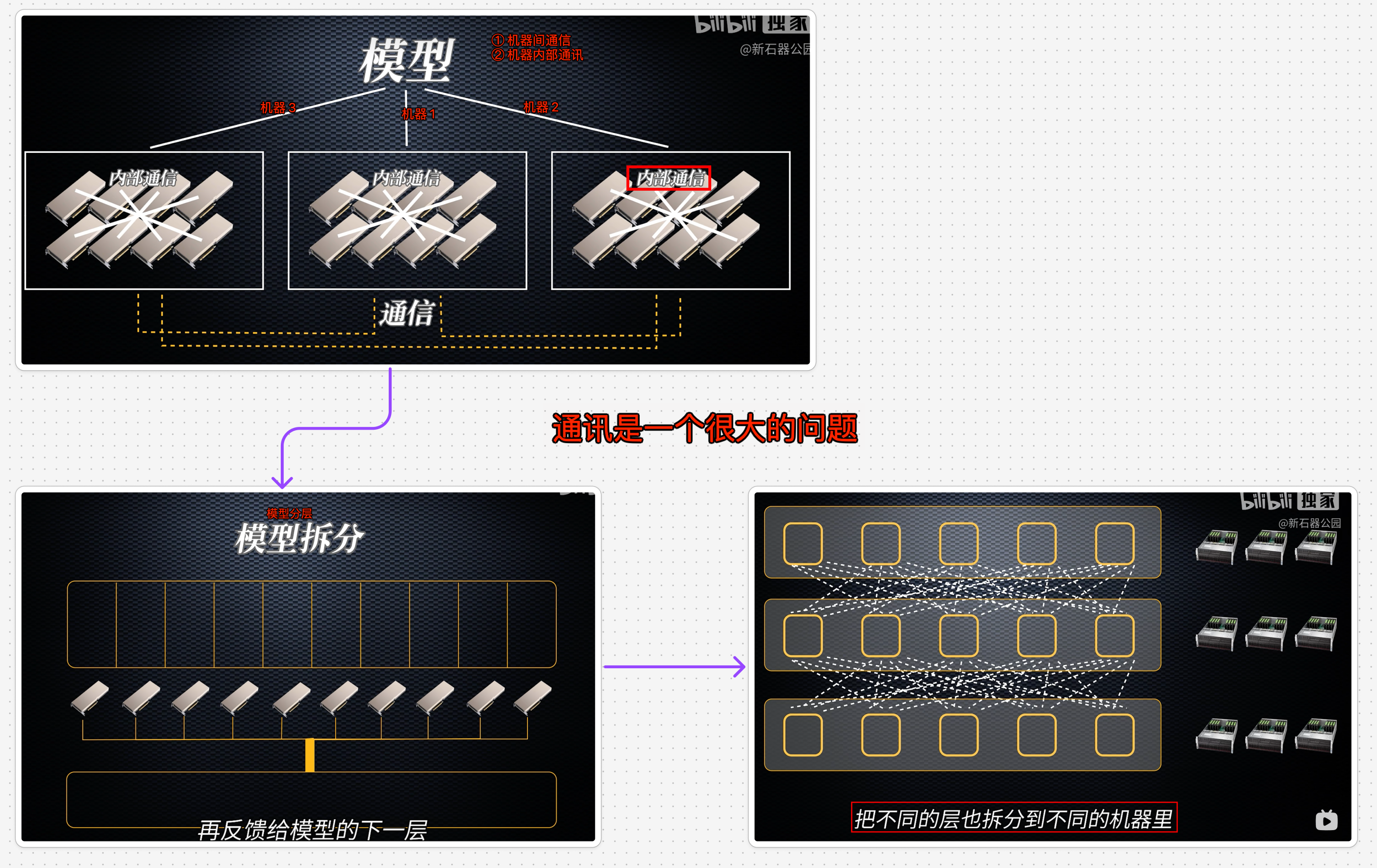
5. 训练大模型需要考虑哪些工程实现方面的挑战?

B 站上看的一个视频其实只是冰山一角,需要考虑的东西那太多了
训练大模型确实面临许多工程实现方面的挑战。以下是一些主要需要考虑的方面:
- 计算资源管理
- 高效调度和利用大规模GPU/TPU集群
- 处理硬件故障和节点失效
- 优化计算和通信的平衡
- 内存和存储优化
- 管理巨大的模型参数和中间状态
- 优化数据加载和预处理流程
- 处理检查点保存和恢复
- 网络通信
- 优化设备间的数据传输
- 处理网络延迟和带宽限制
- 实现高效的集合通信原语
- 分布式训练框架
- 选择和配置合适的分布式训练框架(如PyTorch DDP, DeepSpeed等)
- 实现自定义的分布式训练策略
- 确保不同设备间的同步和一致性
- 数据管理
- 高效处理和存储TB级别的训练数据
- 实现动态数据加载和预处理
- 确保数据的质量和多样性
- 监控和调试
- 实时监控训练进度和硬件状态
- 诊断和解决分布式环境中的问题
- 收集和分析大规模训练日志
- 模型评估和分析
- 设计和实现大规模模型的评估流程
- 分析模型性能和行为
- 可视化和解释模型输出
- 版本控制和实验管理
- 管理复杂的代码库和配置
- 追踪和复现实验结果
- 协调多人协作的开发过程
- 部署和服务
- 将训练好的大模型高效部署到生产环境
- 优化推理性能和延迟
- 实现模型更新和版本控制
- 安全性和隐私
- 保护训练数据和模型参数的安全
- 实现联邦学习等隐私保护技术
- 防范对抗性攻击和模型窃取
- 成本控制
- 优化计算资源使用,降低训练成本
- 评估不同训练策略的成本效益
- 管理云服务和硬件资源的预算
- 可扩展性设计
- 设计能够适应不同规模模型的训练系统
- 实现模块化和可配置的训练流程
- 为未来更大规模的模型做准备
- 这些挑战需要深厚的系统工程知识、分布式计算经验以及对机器学习的深入理解。
- 成功训练大模型通常需要一个多学科团队的紧密合作,包括机器学习研究者、系统工程师、硬件专家等。
- 随着模型规模的不断增长,这些挑战也在不断演变,推动着相关技术的持续创新。