嵌入模型
#2026/01/01 #ai
把文字变成计算机能“理解“的数字
目录
- 一、什么是嵌入模型?先从问题出发
- 二、嵌入模型的作用:翻译官
- 三、什么叫“准确的表示“?
- 四、嵌入模型的多种用途
- 五、嵌入模型的实际应用场景
- 六、嵌入的“维度“是什么意思?
- 七、代码示例:实际使用嵌入模型
- 八、嵌入的“层次“理解
- 九、核心要点总结
- 十、下一步
- 类比总结:
一、什么是嵌入模型?先从问题出发
1. 计算机不懂人类语言
想象你要让计算机处理这样一段评论:
"This vacuum cleans great!"(这台吸尘器清洁效果很棒!)
"The weak suction left dirt behind"(吸力太弱,留下了灰尘)
计算机看到的只是一堆字符,它不知道:
- 哪条评论是好评,哪条是差评
- 两条评论说的是不是同一类产品
- 它们在含义上有什么关系
这就是问题所在:文本数据是非结构化的,很难处理。
二、嵌入模型的作用:翻译官
核心功能
嵌入模型就像一个“翻译官“,它能把文本翻译成计算机能处理的数字(向量):
输入文本
↓
嵌入模型(翻译过程)
↓
数值表示(一串数字)
如图所示,这个过程叫做嵌入(embedding)。

图 :使用嵌入模型将文本输入(如文档、句子和短语)转换为数值表示,即嵌入
举个例子
# 输入
"Best movie ever!"
# 经过嵌入模型处理后,变成:
[0.23, 0.87, -0.45, 0.62, ...] # 比如512个数字
这串数字就是这段文本的嵌入向量,它试图捕捉文本的含义。
三、什么叫“准确的表示“?
语义相似性:核心目标
嵌入模型的主要目标是:尽可能准确地将文本数据表示为嵌入向量。
“准确“是什么意思?
我们想要捕捉文档的语义本质(semantic essence),也就是它的含义。具体来说:
- ✅ 相似的文档 → 向量应该很接近
- ❌ 不相关的文档 → 向量应该离得很远
可视化理解
想象一个二维平面(实际是高维空间):
好评区域
┌──────────────────┐
│ "Best movie!" │
│ "Great product!" │
└──────────────────┘
差评区域
┌──────────────────┐
│ "Horrible!" │
│ "Waste of money" │
└──────────────────┘
如图所示,含义相似的文本在空间中会聚集在一起。

图 :语义相似性的理念是,我们期望具有相似含义的文本数据在 n 维空间中(这里展示了两个维度)彼此更接近
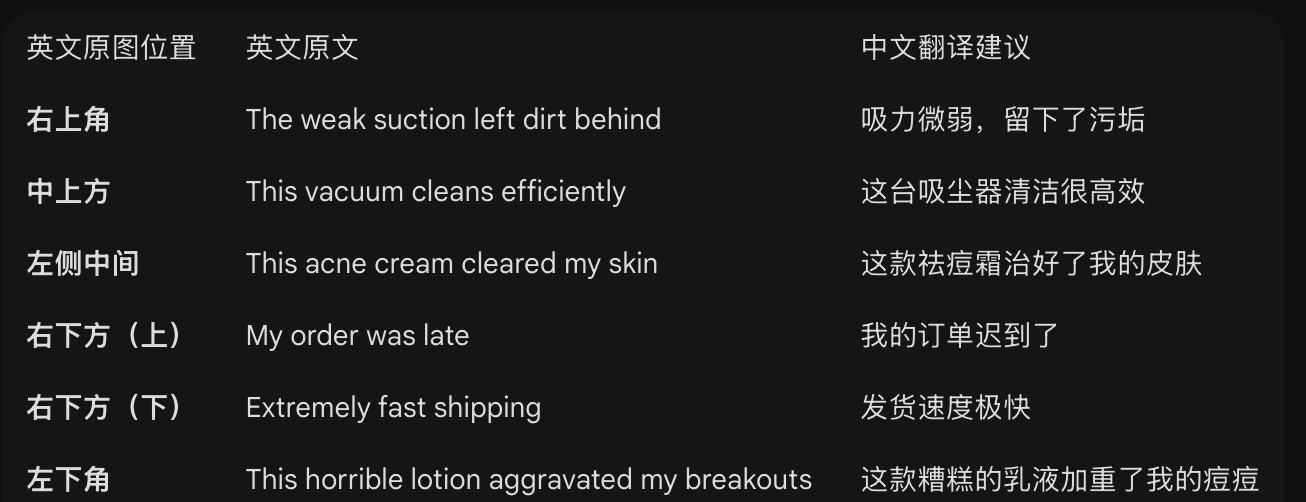

图:除了语义相似性,嵌入模型还可以被训练以关注情感倾向。在该图中,负面评价(红色)彼此接近,并与正面评价(绿色)明显不同
四、嵌入模型的多种用途
根据任务目标调整
嵌入模型可以针对不同目的训练:
1. 语义相似度任务
目标:找到意思相近的文本
"I love cats" 和 "I adore felines" → 距离很近
2. 情感分类任务
目标:区分情感倾向
好评:"Best movie ever!" → 正向区域
差评:"Waste of time" → 负向区域
关键点:不同任务需要不同的嵌入模型,因为关注的特征不同。
五、嵌入模型的实际应用场景
在本书中,我们已经在多个地方用到了嵌入模型:
1. 监督分类(第4章)
# 判断电影评论是好评还是差评
"This movie is amazing!" → 嵌入 → 分类器 → 好评
2. 无监督聚类(第5章)
# 把相似的新闻文章自动分组
体育新闻 → 一堆
科技新闻 → 另一堆
3. 语义搜索(第8章)
# 用户搜索:"如何修复漏水的水龙头"
# 找到最相关的文档,即使用词不完全相同
4. 增强ChatGPT记忆(RAG)
# 给ChatGPT提供相关背景知识
# 让它基于特定文档回答问题
六、嵌入的“维度“是什么意思?
向量的长度
嵌入向量通常包含几百到上千个数字:
128维: [0.2, 0.8, ..., 0.5] # 128个数字
512维: [0.3, 0.7, ..., 0.2] # 512个数字
1024维: [0.1, 0.9, ..., 0.4] # 1024个数字
维度取决于底层的嵌入模型。
类比理解:
- 想象用一组数字来描述一个人
- 1维:只记录身高 → 信息很少
- 512维:记录身高、体重、年龄、性格等512个特征 → 信息丰富
维度越高,能捕捉的信息越细致(但也需要更多计算资源)。
七、代码示例:实际使用嵌入模型
使用sentence-transformers包
from sentence_transformers import SentenceTransformer
# 1. 加载嵌入模型
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
# 2. 将文本转换为嵌入向量
texts = [
"Best movie ever!",
"I love this product!",
"Terrible waste of money"
]
embeddings = model.encode(texts)
# 3. 查看结果
print(embeddings.shape) # (3, 768) - 3个文本,每个768维
# 4. 计算相似度
from sklearn.metrics.pairwise import cosine_similarity
similarity = cosine_similarity(embeddings)
print(similarity)
# 前两个文本(都是好评)相似度高
# 第三个(差评)与前两个相似度低
八、嵌入的“层次“理解
书中提到了不同抽象层次的嵌入:
1. 词嵌入(Word Embedding)
"cat" → [0.2, 0.8, 0.3]
一个词 = 一个向量
2. 句子嵌入(Sentence Embedding)
"I love cats" → [0.5, 0.7, 0.2]
一个句子 = 一个向量
3. 文档嵌入(Document Embedding)
"整篇文章..." → [0.3, 0.6, 0.1]
整个文档 = 一个向量
本章重点:我们主要讨论文本嵌入(句子和文档级别)。
九、核心要点总结
三个关键概念
- 嵌入模型的作用:把文本转换成数字向量
- 语义相似性:相似文本的向量应该接近
- 任务导向:不同任务需要不同的嵌入模型
为什么重要?
嵌入模型是LLM应用背后的核心驱动力,它们:
- 使计算机能“理解“文本含义
- 支撑搜索、分类、聚类等应用
- 让我们能在海量数据中快速找到相关信息
十、下一步
本章后续内容将深入探讨:
- 对比学习:
- 嵌入模型是如何训练的
- 构建嵌入模型:
- 如何从头创建自己的模型
- 微调嵌入模型:
- 如何让模型适应特定领域
类比总结:
想象嵌入模型是一个超级翻译器:
- 输入:人类的语言(文本)
- 输出:计算机的语言(数字向量)
- 目标:让相同含义的东西在“数字世界“里也靠得很近
理解了这个核心思想,你就掌握了嵌入模型的本质!