“语言人工智能” 的演化
#2025/12/25 #ai
目录
- 1. 什么是语言人工智能
- 2. 如何使计算机能够表示和生成语言
- 3.
词袋模型→ 其实就是对象或者哈希表 - 4. 如何体现
语义 - 5. 嵌入的类型
- 6. word2vec → 使用注意力机制
编解码上下文 - 7. “Attention Is All You Need” → Transformer 架构
- 8. 表示模型:仅编码器模型 → BERT 模型
- 9. 生成模型:仅解码器模型
- 10. 生成式 AI 元年
1. 什么是语言人工智能
语言人工智能就是让计算机不再只认代码,而是能像人一样听懂、理解并书写人类语言的技术。更简单来说:它就是“懂人话”的机器大脑
想象一下,你面前有一台电脑:
- 普通电脑:
- 像个死板的计算器。你必须输入精确的指令(比如按特定的按钮或写代码),它才会动。它不“懂”你,它只认代码。
- 语言人工智能:
- 像个“博览群书的翻译官”。
- 你直接用平时说话的方式(自然语言)跟它聊天,它不仅能听懂你的意思,还能像真人一样回答你、帮你写作业、甚至帮你翻译外语。
- 像个“博览群书的翻译官”。
2. 如何使计算机能够表示和生成语言

难点:
- 文本本质上是
非结构化的,当用0和1(单个字符)表示时就会失去其含义 - 如何以
结构化的方式表示语言,使计算机能够更容易地使用

3. 词袋模型 → 其实就是对象或者哈希表
语言人工智能历史始于一种名为词袋(bag-of-words)的技术,这是一种表示非结构化文本的方法
词袋模型的第一步是 分词 (tokenization),即将句子拆分成单个词或子词( 词元 ,token)

创建词表 ,计算词表

然后计算每个词表出现的次数,使用向量表示

4. 如何体现语义
词袋存在一个明显的缺陷。它仅仅把语言视为一个几乎字面意义上的“词袋”,而忽略了文本的语义特性和含义。
4.1. 朋友圈
传统的“词袋模型”只是数单词出现的次数,它不理解含义。而 Word2Vec(词嵌入) 则是通过观察一个词的“朋友圈”来定义这个词。
- 黄金法则: “看一个人的品行,要看他交什么样的朋友。”
- 训练方法: 电脑阅读海量文字(比如整个维基百科)
- 发现“苹果”经常和“好吃”、“多汁”、“水果”出现在一起;而“手机”经常和“充电”、“屏幕”、“信号”出现在一起。
- 结果: 经常一起出现的词,在电脑里的“距离”就会被拉近。
4.2. 词嵌入:给单词一套“属性打分表” → word2vec(词向量)
- 你可以把“
词嵌入(Embedding)”想象成游戏里的人物属性面板
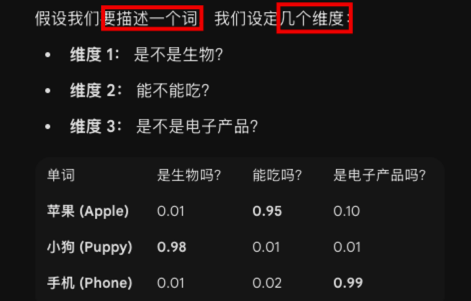
- 每个单词就变成了一串数字(例如苹果就是
[0.01, 0.95, 0.10])。 - 这串数字就是向量
- 在真实的 AI 模型里,这种维度可能有
几百甚至几千个- 虽然
人类无法直观理解每个维度代表什么,但电脑能通过这些数字精准捕捉语义。
- 虽然
当单词变成了向量(数字),奇迹就发生了:我们可以对单词做加减法了!
最经典的例子是:

4.3. embedding 、word2vec 、 嵌入
- 嵌入 (embedding)这个概念来捕捉文本含义的技术之一
嵌入是数据的向量表示,试图捕捉数据的含义。- 为此,word2vec 通过在大量文本数据(如整个维基百科)上训练来学习词的
语义表示。
- 为此,word2vec 通过在大量文本数据(如整个维基百科)上训练来学习词的
为了生成这些语义表示,word2vec 利用了 神经网络 技术。神经网络由处理信息的多层互连节点组成。
如图 1-6 所示,神经网络可以有多个“层”,每个连接都有一定的权重,这些权重通常被称为模型的 参数

图 1-6:神经网络由互连的多层节点组成,每个连接都是一个线性方程
利用这些神经网络,word2vec 观察在给定句子中哪些词倾向于出现在其他词旁边,进而据此生成词嵌入。
换言之: 如果两个词各自的相邻词集合有更大的交集,它们的词嵌入向量就会更接近
为词表中的每个词分配一个向量嵌入,比如说每个词有 50 个随机初始化的值。我们从训练数据中取出词对(pairs of words),用模型尝试预测它们是否可能在句子中相邻

4.4. 示例:词嵌入
apple和 baby
baby、newbornhuman得分可能很高- 而
apple在这些属性上的得分则较低。

如果我们将这些词嵌入压缩成二维表示 ,如下图,你会发现含义相似的词往往会更接近,

那如果将这些词嵌入压缩到 n 维空间 呢?
5. 嵌入的类型
- 词元嵌入
- 这是给每一个词(或者词的一部分)制作一个专属的数字代码
- 好比你给“猫”、“狗”、“跑”这每个词都发一张身份证,计算机会通过这些数字知道“猫”和“狗”是相似的动物
- 句子或文档嵌入
- 这是给整句话或者整篇文章制作一个数字代码,用来表示这一大段话整体在讲什么
- 又比如
词袋模型在文档层面创建嵌入,因为一个嵌入表示的是整个文档word2vec为每个词生成一个嵌入

为什么要分这些类型?因为应用场景不同。
- 如果你想让电脑分析“bank”这个词是指“银行”还是“河岸”,你需要研究词嵌入,看它周围搭配了什么词。
- 如果你想让电脑把
一堆新闻自动分成“体育新闻”和“财经新闻”,或者判断一条评论是夸奖还是批评,你就需要文档嵌入,让电脑通过一个整体的数字向量来判断整篇文章的意思
6. word2vec → 使用注意力机制编解码上下文
word2vec就像是一个静态的哈希表(HashMap)- 问题:
- 单词
bank在数据库里对应一个固定的向量(Vector), 无论原本是在说“河岸”还是“银行”,查出来的向量都是一样的。这被称为“静态嵌入”。
- 单词
- RNN 的尝试:
- 你可以把 RNN 想象成一个状态机。它读取输入序列(比如 “I love llamas”),
每读一个词,就更新一次内部的“隐藏状态”(Hidden State)
- 你可以把 RNN 想象成一个状态机。它读取输入序列(比如 “I love llamas”),
- 致命缺陷:
- RNN 采用的是 Encoder-Decoder(编码器-解码器)架构。
编码器读完整个句子后,必须把所有信息压缩成唯一的一个上下文向量(Context Vector)传递给解码器- 问题:是当输入句子很长时,会丢失一些信息。因为 RNN 只能记住
有限长度的信息,而长句子需要记住的信息量很大
6.1. 示例
示例:“I love llamas”(我喜欢美洲驼)这个英语句子翻译成荷兰语 “Ik hou van lama’s”

该架构中的每个步骤都是 自回归 (auto-regressive)的。在生成下一个词时,该架构需要使用所有先前生成的词作为输入。

图 1-12:每个之前输出的词元都被用作生成下一个词元的输入
输入是如何按顺序一次处理一个词的,输出也是如此,比如下图中的 1,2,3 → 4 5 6 7

图 1-13:使用 word2vec 嵌入,生成用于表示整个序列的上下文嵌入
类比:
- 没有注意力机制(RNN): 就像用一个固定大小的
buffer来缓存整个请求体。如果请求体太大,前面的数据就被挤丢了,或者所有数据混在一起分不清谁是谁
6.2. 引入注意力机制
注意力机制通过让解码器在生成每个词的时候,都去关注编码器输出的所有词,从而解决了传统 RNN 在处理长句子时丢失信息的问题,注意力权重或分数,如下图

图 1-14:注意力机制使模型能够“注意”序列中彼此相关程度更高或者更低的部分
解码步骤中添加这些注意力机制,RNN 可以为输入序列中的每个词生成与潜在输出相关的信号。这并不仅仅是将上下文嵌入传递给解码器,而是传递所有输入词的隐藏状态。如图 1-15 所示。

图 1-15:在生成 Ik、hou 和 van 这些词之后,解码器的注意力机制使其能够关注到 llamas 这个词,进而生成它的荷兰语译文 lama's
因此,在生成“Ik hou van lama’s”的过程中,RNN 会追踪它在进行翻译时主要关注的词。
7. “Attention Is All You Need” → Transformer 架构
相比 word2vec,基于注意力的 RNN 架构可以通过“关注”整个句子,更好地表征文本的序列特性及其上下文。但这种序列特性有两个缺点
① 不利于模型训练过程中的并行化
- 是串行的(Sequential)。你必须先处理第 1 个词,算出状态,才能处理第 2 个词。这意味着 GPU 这种擅长并行计算的硬件无法火力全开,训练非常慢。
- 后面提到的
Transformer 架构允许模型一次性把整句话输入进去,同时处理所有单词
②以及在处理长序列时容易丢失信息
与 RNN 相比,Transformer 支持并行训练,这大大加快了训练速度。
以码农容易理解方式解释: 从 “单线程串行处理” 到 “大规模并行处理” 的架构重构
在 Transformer 中,编码和解码组件相互堆叠,如图 1-16 所示。这种架构仍然是自回归的,每个新生成的词都被模型用于生成下一个词。

图 1-16:Transformer 由堆叠的编码器和解码器块组合而成,输入依次流经每个编码器和解码器
7.1. 自注意力
既然不再按顺序一个一个读词,那模型怎么知道“单词 A”和“单词 B”之间的关系(比如语序和依赖关系)呢?答案就是 自注意力 (Self-Attention)。
- 什么是自注意力?
- 在上一节的 RNN 中,注意力主要用于“输出”看“输入”。而在 Transformer 的编码器中,引入了自注意力。
- 意思是:输入序列中的每一个词,都要去“关注”输入序列中的其他所有词,计算它们之间的相关性
自注意力可以关注单个序列内部的不同位置,从而更高效且准确地表示输入序列,如图 1-18 所示。它可以一次性查看整个序列,而不是一次处理一个词元。

图 1-18:自注意力机制能关注到输入序列的所有部分,使其可以在单个序列内同时“查看”前后文内容
再举个例子
想象你在读句子 “The animal didn't cross the street because it was too tired.”
◦ 当模型处理 “it” 这个词时,自注意力机制会同时查看句子里的其他词。
◦ 它会发现 “it” 和 “animal” 的关联度(权重)非常高,和 “street” 的关联度较低。
◦ 于是,模型就把 “animal” 的信息融合进了 “it” 的表示中
7.2. 编码器块 → 负责理解 → 自注意力 和 前馈神经网络
- 它由多个层堆叠而成(比如 6 层或 12 层)
- 每一层里都有 自注意力 和 前馈神经网络 (Feed-Forward NN)。
- 它的任务是把输入的自然语言转换成一堆
富含语义信息的数字矩阵。

图 1-17:编码器块围绕自注意力来生成中间表示
7.3. 解码器 → 负责“生成”。
与编码器相比,解码器多了一个注意力层,用于关注编码器的输出(以便找到输入中相关的部分)。
它的任务是根据编码器的信息,一个词一个词地蹦出结果(自回归)
虽然输入(编码器)可以一次性并行处理,但输出(解码器)在生成时必须遵守时间顺序(你不能在写第一个字之前就先写出第三个字)

图 1-19:解码器具有一个附加的注意力层,用于关注编码器的输出
如图 1-20 所示,解码器中的自注意力层会掩码未来的位置,这样在生成输出时就只会关注之前的位置,从而避免信息泄露。

图 1-20:仅关注之前的词元以避免“看到未来”
关于
作弊和掩码,可见 12. Transformer 中的 “作弊” 和 13. 掩码自注意力机制
8. 表示模型:仅编码器模型 → BERT 模型
- 如果说上一节讲的 Transformer(编码器+解码器)
是一个既能听懂(编码)又能说话(解码)的“全能翻译官”, - 那么 BERT 模型,就是一个极致的“阅读理解专家”。
这一节主要介绍了一种被称为 “仅编码器模型”(Encoder-Only Model) 的架构,其中最著名的代表就是 BERT。
8.1. 架构:只要一半,为了更专注
在 Transformer 的原始架构中,左边是编码器(负责理解输入),右边是解码器(负责生成输出)。
- BERT 的做法:
- 工程师们发现,如果我们不打算让模型写文章或做翻译,而是只想让它深刻理解这句话是什么意思(比如判断这句话是夸人还是骂人),那么我们根本不需要右边的“解码器”。
- 结果:
- 于是 BERT 直接砍掉了 Transformer 的右半部分,只保留了左边的编码器(Encoder) 堆叠在一起。
- 形象理解:
- 这就像一个专业的审稿人。
- 他不需要开口写作,他的所有精力都用来阅读、分析文章的结构、含义和情感。
8.2. 核心能力:双向理解(Bidirectional)与“完形填空”
这是 BERT 最革命性的地方。之前的模型(如 GPT)在读书时,通常是从左到右一个字一个字读,就像我们无法预知未来一样。但 BERT 作为“仅编码器”模型,它有一项特权:它可以同时看到整句话的所有内容。
书中提到了 BERT 的训练绝招——掩码语言建模(Masked Language Modeling, MLM)。
- 以前的训练(GPT类): 猜下一个词是什么?
- 输入:“我爱吃……” -> 猜:“苹果”。
- BERT的训练(MLM): 完形填空。
- 做法:
- BERT 会随机把句子里的某个词挖掉(用
[MASK]遮住),然后利用这个词前面和后面的所有信息来推测这个词是什么。
- BERT 会随机把句子里的某个词挖掉(用
- 例子:
- 输入:“今天下雨了,所以我带了 [MASK] 出门。”
- 推理:
- BERT 会同时看到前面的“下雨”和后面的“出门”,综合推断出中间应该是“伞”。
- 做法:
- 工程意义:
- 这种机制迫使模型必须深刻理解上下文的双向(Bidirectional) 关系,而不仅仅是单向预测。
- 这就是为什么它在理解任务上比
GPT(单向)更强的原因。
8.3. 应用模式:预训练 + 微调(Pre-training + Fine-tuning)
BERT 开启了一个新的工程范式,被称为迁移学习。书中展示了这一过程:
- 预训练(读万卷书):
- 让 BERT 在海量文本(如维基百科)上做“完形填空”。
- 这时候它不针对任何具体任务,只是在学习语言本身的规律。这时候的模型叫基座模型。
- 微调(术业有专攻):
- 当你要用 BERT 做具体工作时(比如判断垃圾邮件),你
不需要从头训练。 - 你只需要给这个“博学”的 BERT 看少量的垃圾邮件样本,稍微调整一下参数,它就能立刻成为这方面的专家。
- 当你要用 BERT 做具体工作时(比如判断垃圾邮件),你
BERT 会在句子最前面加一个特殊的 [CLS] 标签(Classification Token)。
你可以把它理解为整个句子的“总代表”或“摘要向量”。当我们要分类整句话(比如判断情感是正面还是负面)时,只需要看这个 [CLS] 标签的输出向量就可以了。
8.4. 中学生/工程师视角的类比
- 生成模型(GPT):
- 像一个作家。他必须一个字一个字往下写,不能回头,专注于流畅地把故事编下去。
- 表示模型(BERT):
- 像一个侦探。他把整个案卷(句子)摊在桌子上,既看开头也看结尾,寻找线索(Mask),目的是为了
还原真相(理解语义),而不是为了写小说。
- 像一个侦探。他把整个案卷(句子)摊在桌子上,既看开头也看结尾,寻找线索(Mask),目的是为了
所以,书中将这类模型定义为 “表示模型”(Representation Model),因为它们的强项是把复杂的文本转换成计算机能深刻理解的数字表示(向量),主要用于分类、搜索、提取信息,而不是用来聊天的。
8.5. 为什么将这类模型(如 BERT)称为 “表示模型”(Representation Model),
主要是为了强调它的核心任务和输出形式与生成模型(如 GPT)截然不同。
简单来说,叫它“表示模型”是因为它的工作就是把“文字”变成“由数字组成的意义代码”(即表示/向量)
我们可以从以下几个角度来理解,为什么书中这样命名:
- 核心任务:只读不写,专注“翻译”含义
- 生成模型(Writer):
- 像 GPT 这样的模型,任务是“
接龙”,它的产出是新的文字。
- 像 GPT 这样的模型,任务是“
- 表示模型(Reader):
- 像 BERT 这样的模型,任务是“
阅读理解”。 - 它读完一句话后,并不需要写出下一句,而是要输出
一串数字(向量)。 - 这串数字就是这句话在计算机眼里的 “数学表示”
- 像 BERT 这样的模型,任务是“
- 主要关注语言的表示,例如创建嵌入,而
通常不生成文本
- 生成模型(Writer):
- 架构原因:只有编码器(Encoder-Only)
- 在 Transformer 架构中,编码器(Encoder) 的作用就是把人类的自然语言“编码”成计算机能处理的
稠密向量(Dense Vector)。 - 解码器(Decoder) 的作用是
根据向量“解码”回自然语言。 - 因为 BERT 这类模型砍掉了解码器,只保留了编码器,所以它只能完成“编码/表示”这一步,无法完成“生成”那一步。因此,称其为“表示模型”非常准确地描述了它的架构特征,。
- 在 Transformer 架构中,编码器(Encoder) 的作用就是把人类的自然语言“编码”成计算机能处理的
- 工程用途:通用特征提取器
- 在软件工程中,你可以把它看作一个
“特征提取器” - 当你把文本扔给它,它吐出来的
不是人话,而是一个高维向量(比如 768 维的数组)。这个向量浓缩了文本的语义、语法和情感信息。 - 为什么叫“表示”? 因为这个向量就是原文本在数学空间里的“代理人”或“代表”(Representation)。
- 后续的分类器(比如判断垃圾邮件)只需要看这个“代表”就能做出判断,而不需要再去分析原始的文本字符。
- 在软件工程中,你可以把它看作一个
总结一下:
- 之所以叫“表示模型”,是因为它不负责创造新的内容,只负责把现有的内容转换(表示)成计算机能懂的、富含语义的数字形式。
- 它是为了让计算机“看懂”而存在的,不是为了“陪聊”的。
8.6. 图文总结
原始的 Transformer 模型:
- 是一个编码器 - 解码器架构,虽然非常适合
翻译任务,但难以用于其他任务,比如文本分类。 - BERT 是一个仅编码器架构
- 专注于
语言表示。这意味着它只使用编码器,完全移除了解码器。
- 专注于

图 1-21:BERT 基座模型的架构,包含 12 个编码器
这些编码器模块与我们之前看到的相同:在自注意力层之后,接上前馈神经网络。输入中包含一个附加词元—— [CLS] (分类词元),用于表示整个输入。通常,我们使用 [CLS] 词元作为输入嵌入(input embedding),用于在特定任务(如分类)上进行模型微调。
这些堆叠起来的编码器很难训练,因此 BERT 采用了一种被称为 掩码语言建模 (masked language modeling)的技术来解决这个问题。
如图 1-22 所示,该方法会掩码部分输入,让模型预测被掩码的部分。这样的预测任务虽然困难,但能让 BERT 为输入序列创建更准确的(中间)表示。 → 所以说像是 完形填空

图 1-22:用掩码语言建模方法训练 BERT 模型
这种架构和训练过程使 BERT 及相关架构在表示依赖上下文的文本方面表现十分出色。BERT 类模型通常用于 迁移学习 (transfer learning),这包括首先针对语言建模进行 预训练 (pretraining),然后针对特定任务进行 微调 (fine-tuning)。
例如,通过在整个维基百科的文本数据上训练 BERT,它学会了理解文本的语义和上下文性质。然后,如图 1-23 所示,我们可以使用该预训练模型,针对特定任务(如文本分类)进行微调。

图 1-23:在掩码语言模型上预训练 BERT 后,我们针对特定任务对其进行微调
预训练模型 的一个巨大优势是 大部分训练工作已经完成。针对特定任务的微调通常计算量较小,且需要的数据更少。
此外,BERT 类模型架构在处理过程中的几乎每一步都会生成嵌入,这使得 BERT 模型成为通用特征提取器,无须针对特定任务进行微调。
像 BERT 这样的仅编码器模型将在本书的多个章节中使用。多年以来,它们一直被用于常见任务,包括
- 分类任务(见第 4 章)、
- 聚类任务(见第 5 章)
- 和语义搜索(见第 8 章)。
在本书中,我们将仅
- 编码器模型称为 表示模型 (representation model),以区别于仅
解码器模型; - 将仅解码器模型称为 生成模型 (generative model)。
需要注意的是,表示模型和生成模型的主要区别并不在于底层架构和工作方式。
表示模型主要关注语言的表示,例如创建嵌入,而通常不生成文本;相比之下,生成模型主要关注生成文本,通常不会被训练用于生成嵌入。
表示模型和生成模型及其组件的区别也会体现在本书的大多数图片中
- 表示模型用
蓝绿色表示,配有一个小向量图标(表示其关注向量和嵌入) - 而生成模型用
粉红色表示,配有一个小对话图标(表示其生成能力)
9. 生成模型:仅解码器模型
- 如果说上一节的 BERT :
- 是一个“阅读理解满分的学霸” (只读不写)
- 生成模型(GPT系列):
- 就是一个“才思泉涌的畅销书作家”(边想边写)。
这一节主要介绍的是 “仅解码器模型”(Decoder-Only Model)。这是目前最火的 ChatGPT、Llama 等大模型所采用的核心架构。
9.1. 架构:只保留“写作”能力
在 Transformer 的原始架构中,右边的解码器(Decoder)原本是用来翻译的,它负责输出翻译后的文字。
- GPT 的做法:
- 工程师们想,既然我们要造一个能说话、能写文章的 AI,那干脆只保留负责“输出”的解码器,把负责“输入理解”的编码器砍掉。
- 结果:
- 这种模型由很多层解码器堆叠而成(比如 GPT-1)。它专注于一件事:根据上文,猜下一个字是什么。
- 即
成语接龙
9.2. 核心原理:超级“自动补全”
你一定用过手机输入法,当你打出“今天天”,输入法会提示“气”,变成“今天天气”。生成模型的工作原理本质上就是这个,但它比输入法聪明亿万倍。
- 自回归(Autoregressive):
- 这是一个听起来很高级但其实很简单的词。意思是模型写文章像接龙一样,写完第一个字,把这个字加到句子里,再根据现在的句子写第二个字,一直循环下去。
- 例子: 比如输入“Tell me something about llamas”(告诉我关于美洲驼的事)。
- 模型不会一下子把整段话变出来,而是一个词一个词地蹦:
- 先蹦出 “
Llamas”,然后是 “are”,然后是 “domesticated”……。
- 先蹦出 “
- 这是一个听起来很高级但其实很简单的词。意思是模型写文章像接龙一样,写完第一个字,把这个字加到句子里,再根据现在的句子写第二个字,一直循环下去。
- 不仅仅是补全:
- 虽然原理是补全,但当模型看过足够多的书(
训练数据)后,它不仅能补全句子,还能补全逻辑、补全代码、补全故事。
- 虽然原理是补全,但当模型看过足够多的书(
9.3. 从“小作家”到“大文豪”:规模的进化
这一节提到了一个关键概念:LLM(大语言模型)中的“大”。
- GPT-1:
- 参数量 1.17 亿。这就像一个小学生,能写简单的句子。
- GPT-2:
- 参数量 15 亿。这就像一个初中生,能写通顺的作文了。
- GPT-3:
- 参数量 1750 亿。这就像一个博览群书的大学教授。量变引起质变,当参数量大到一定程度,模型突然“
涌现”出了惊人的能力。
- 参数量 1750 亿。这就像一个博览群书的大学教授。量变引起质变,当参数量大到一定程度,模型突然“

9.4. 进化:从“续写”到“聊天”
早期的生成模型(如 GPT-3 原始版)有个毛病:它是个“杠精”或者“复读机”。
- 问题:
- 你问它“美国首都是哪里?”,它可能会以为你在玩成语接龙,接着生成“中国首都是哪里?英国首都是哪里?”因为它以为任务是补全问题列表。
- 解决方案(指令微调):
- 书中提到,为了让它变成聊天机器人(如 ChatGPT),我们需要对它进行
特训,让它学会遵循指令(Instruction Following)。- 现在的模型(指令模型/对话模型)不再只是呆呆地补全,而是试图回答你的问题。你问“美国首都是哪里?”,它会回答“华盛顿”。
- 书中提到,为了让它变成聊天机器人(如 ChatGPT),我们需要对它进行
9.5. 一个重要的限制:上下文长度(Context Length)
这节还提到了一个概念叫上下文窗口。
- 你可以把它想象成模特的“短期记忆容量”
- 定义:
- 它是输入(你的问题)+ 输出(它的回答)的总长度限制。
- 影响:
- 就像一个人记性有限,如果你跟它聊了三天三夜,前面的话它可能就忘了,因为超出了它的“上下文长度”,旧的记忆被挤出去了。
9.6. 阅卷老师 vs 考生
- BERT(表示模型):
- 是阅卷老师,看完整张卷子打分(分类、理解)。
- **GPT(生成模型):
- 是考生,笔不离手,根据题目一个字一个字地把作文写出来。
这就是为什么现在的 ChatGPT 等模型叫“生成式 AI”,因为它们的核心能力就是预测下一个词,从而创造出全新的内容。
9.7. 图文总结
- 生成式预训练 Transformer,现在被称为 GPT-1,
- GPT 因其生成能力而得名。如图 1-24 所示,它与 BERT 编码器堆叠架构类似,堆叠了多个解码器块。

图 1-24:GPT-1 架构。GPT-1 使用了仅解码器架构,去掉了编码器注意力块
- 生成式 LLM 作为一种序列到序列(sequence-to-sequence,
Seq2Seq)的文本生成系统,其核心机制是接收文本输入并尝试自动补全。 - 尽管自动补全功能很实用,但这类模型真正的强大之处在于经过训练成为聊天机器人。
- 与其只是补全文本,不如将它们训练得能够回答问题。
- 通过
微调这些模型,我们可以创建能够遵循人类指示的 指令模型 (instruct model)或 对话模型 (chat model)。
如图 1-26 所示,由此创建的模型接收用户查询(提示词,prompt),输出最可能符合该提示词的响应。因此,你经常会听到生成模型被称为 补全模型 (completion model)。

图 1-26:生成式 LLM 接收输入并尝试补全。对于指令模型来说,则不仅仅是自动补全,而是试图回答问题
这些补全模型的一个要素是所谓的 上下文长度 (context length),也称为 上下文窗口 (context window)。如图 1-27 所示,上下文长度代表模型可以处理的最大词元数量。如果我们有较大的上下文长度,就可以将整个文档传递给 LLM。需要注意的是,由于这些模型的自回归特性,当生成新的词元时,当前的上下文长度会增加。

图 1-27:上下文长度是 LLM 能处理的最长上下文
9.8. 几个疑问❓
9.8.1. 所谓“对回答微调”,怎么解释?
你提到的“对回答微调”,在书中被称为 偏好调优(Preference Tuning) 或 对齐(Alignment)。这是大模型训练的“第三步”(前两步是预训练和指令微调`)。
如果说“预训练”是让模型学会说话,“指令微调”是让模型学会听懂命令,那么“对回答微调”就是让模型学会“看眼色”,不仅要答对,还要答得让人满意。
- 为什么要这样做?
- 模型在学会说话后,可能会生成很多种回答。有的回答虽然正确但很粗鲁,有的回答有种族歧视,有的回答啰里啰嗦。
- 我们需要告诉模型:“在这一堆可能的回答里,人类更喜欢哪一种。”
- 具体怎么做?(RLHF 与 DPO) 书中提到了两种主要方法:
- 奖励模型(Reward Model): 我们可以训练一个“裁判模型”。给它看两个回答,让它判断哪个更好。然后用这个裁判来给大模型打分。如果大模型得了高分,就奖励它;得了低分,就惩罚它。这就像训练小狗,做对了给骨头(强化学习 PPO)。
- 直接偏好优化(DPO): 这是一种更现代的方法。不再需要额外的“裁判模型”,直接给大模型看“好回答”和“坏回答”的数据对,告诉它:“以后多生成像A这样的,少生成像B这样的”。
总结: 所谓“对回答微调”,就是调整模型的参数,让它的输出风格、价值观更符合人类的喜好(比如更有用、更安全、更礼貌)。
9.8.2. 预训练、表示模型、生成模型,是什么关系?
这三个词描述的维度不同。我们可以用“教育阶段”和“职业分工” 来理清它们的关系。
- 预训练(Pre-training):这是“教育阶段”。
- 无论是表示模型还是生成模型,它们出生时都是一张白纸。预训练就是让它们去“读万卷书”(海量数据),学习词汇、语法和世界知识。
- 共同点: 它们都要经历预训练。
- 表示模型(Representation Model) vs. 生成模型(Generative Model):这是“职业分工”。
- 表示模型(如 BERT):
- 架构: 仅编码器(Encoder-Only)。
- 职业: 阅读理解专家。它不擅长写文章,但擅长把文字转换成数学向量,用于分类、搜索或情感分析。
- 预训练方式: 做“完形填空”(把句子中间挖个洞让它填)。
- 生成模型(如 GPT):
- 架构: 仅解码器(Decoder-Only)。
- 职业: 作家/聊天机器人。它擅长一个字接一个字地写下去。
- 预训练方式: 做“文字接龙”(猜下一个字是什么)。
- 表示模型(如 BERT):
一句话总结: “预训练”是它们上学的过程;毕业后,有的变成了擅长阅读的“表示模型”,有的变成了擅长写作的“生成模型”。
9.8.3. 既然叫“预”训练,那么有“后”训练,或者“正在”训练吗?
- 预训练 (Pre-training):
- 指的是在海量通用数据上进行的初始训练。这是最耗时、最昂贵的阶段(比如 Llama 2 用了 2 万亿个词元)。
- 之所以叫“预”(Pre),是因为它是在针对具体任务之前的准备工作。
- 后训练 (Post-training):
- 书中明确提到,微调(Fine-tuning) 有时也被称为 后训练。
- 这包括我们在第1个问题中提到的“监督微调(SFT)”和“偏好调优”。
- 这是在预训练的基础上,让模型学习特定技能(如写代码、看病)或对齐人类价值观。
- 正在训练 (Online Learning / Inference):
- 通常情况下,模型一旦发布(推理阶段),它的参数就固定了,不再进行永久性的“训练”。
- 你和它聊天时,它
并没有在“修改大脑皮层”。 - 但是,
- 书中提到了上下文学习(In-context Learning)。
- 当你把新知识写在提示词里发给模型时,它能短暂地学会这个知识并回答你,
- 但这只是“临时记忆”,关掉窗口就忘了,并不改变模型内部的参数。
类比一下:
- 预训练: 你在大学里通过读课本学习通识知识。
- 后训练: 你入职后,公司给你进行的岗前培训(
微调)。 - 推理(正在使用):
- 你开始工作了。虽然你每天在处理新邮件(上下文),但你的学历和核心技能(模型参数)通常不会因为发了一封邮件就立刻改变,除非你回炉重造(重新训练)。
10. 生成式 AI 元年
这些开源基座模型通常被称为 基础模型 (foundation model),可以针对特定任务,比如遵循指令进行微调。

图 1-28:生成式 AI 元年全景图。注意:图中仍有许多模型未列出