BPE (字节对编码):篇 2
#2026/01/01 #ai
这一节 “” 是为了解决我们上一节遇到的“致命 Bug”——如何处理训练集中没见过的单词(Unknown Words)。
在上一节的简单分词器中,遇到没见过的词程序直接崩溃(KeyError)或者只能无奈地用 <|unk|> 代替,这会丢失大量信息
BPE(Byte Pair Encoding) 提供了一个更优雅的方案:“如果我不认识这个单词,那我就把它拆成我认识的零件(子词)。”
GPT-2、GPT-3 和 ChatGPT 的原始模型都使用这种技术。为了高性能,Python 社区通常不自己手写 BPE 的底层循环,而是直接调用 OpenAI 开源的高性能库 tiktoken
底层由
Rust编写,速度极快
目录
- 1. 准备工作:引入强力外援
tiktoken - 2. 实战:编码与解码 (Encode & Decode)
- 3. BPE 的核心魔法:如何处理“未知词”?
- 4. BPE 是怎么构建出来的?(算法原理简述)
1. 准备工作:引入强力外援 tiktoken
书中推荐使用 tiktoken 库,它是目前处理 GPT 系列模型分词的标准工具。
核心逻辑: 我们不再自己维护那个简单的 vocab 字典了,而是加载 OpenAI 已经在大规模数据上训练好的、成熟的 BPE 编码器。
# 首先需要在终端安装库: pip install tiktoken
from importlib.metadata import version
import tiktoken
# 打印版本,确保环境没问题
print("tiktoken version:", version("tiktoken"))
# 1. 加载预训练的 BPE 编码器
# "gpt2" 是编码器的名称,用于 GPT-2 和 GPT-3
# 这相当于加载了一个极其庞大的、极其智能的“字典”
tokenizer = tiktoken.get_encoding("gpt2")
2. 实战:编码与解码 (Encode & Decode)
BPE 的用法和我们之前写的 SimpleTokenizer 几乎一样,也是 encode (文本转数字) 和 decode (数字转文本)。
代码演示:
# 待处理的文本
# 注意:这里包含了一个故意编造的生僻词 "someunknownPlace"
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
# 2. 编码:将文本转换为 整数ID列表
# allowed_special={'<|endoftext|>'} 告诉分词器:
# "<|endoftext|>" 是特殊指令,不要把它拆碎了,要识别为一个整体。
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(f"编码后的 ID列表: {integers}")
# 输出示例: [15496, 11, 466, ... 50256, ... 13]
# 3. 解码:将 整数ID列表 还原为文本
strings = tokenizer.decode(integers)
print(f"解码后的文本: {strings}")
# 输出: Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace.
关键观察点:
<|endoftext|>的 ID:- 在 GPT-2 的 BPE 词表中,
<|endoftext|>对应的 ID 是 50256。这也是词表中的最大 ID(词表大小为50257)。
- 在 GPT-2 的 BPE 词表中,
- 处理未知词:
- 没有报错!它成功处理了 “someunknownPlace”。
3. BPE 的核心魔法:如何处理“未知词”?
这是本节最精华的部分。为什么 BPE 不需要 <|unk|> 标签也能处理未知单词?
原理:
- 它把单词看作是积木(Subwords/子词) 搭成的。
- 如果它不认识 “
someunknownPlace” 这个整体,它就尝试把它拆成它认识的更小的片段。最坏的情况,它会拆成单个字母(字符),而单个字母它肯定认识。
- 如果它不认识 “
代码验证(可视化拆解过程): 让我们用书中的练习题单词
"Akwirw ier"来演示这个拆解过程。
# 一个完全陌生的单词
unknown_word = "Akwirw ier"
# 1. 对其进行编码
token_ids = tokenizer.encode(unknown_word)
print(f"原始单词: {unknown_word}")
print(f"编码后的 ID: {token_ids}")
# 2. 这里的魔法是:我们遍历每一个 ID,单独解码它
# 看看机器到底把这个词拆成了什么样
print("\n--- 拆解分析 ---")
for tid in token_ids:
# 将单个 ID 解码回文本片段
part = tokenizer.decode([tid])
print(f"ID: {tid:<6} -> 子词: '{part}'")
# 3. 验证还原
print(f"\n还原验证: '{tokenizer.decode(token_ids)}'")
运行结果分析(参考书中图 2-11): 输出可能会像这样(取决于具体的分词逻辑):
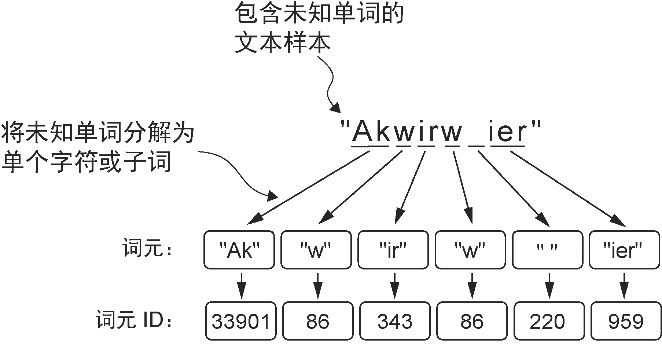
- ID: 33901 -> 子词: ‘Ak’
- ID: 86 -> 子词: ‘w’
- ID: 343 -> 子词: ‘ir’
- ID: 86 -> 子词: ‘w’
- ID: 220 -> 子词: ’ ’ (空格)
- ID: 959 -> 子词: ‘ier’
结论:
- BPE 分词器把
"Akwirw ier"拆成了["Ak", "w", "ir", "w", " ", "ier"]这几个它认识的子词。这就是 BPE 强大的泛化能力——它不需要见过每一个单词,只要见过组成单词的“零件”即可。
代码参考
ch02/02/test_unknown_word.py
4. BPE 是怎么构建出来的?(算法原理简述)
虽然我们直接用了 tiktoken,但理解其背后的构建逻辑有助于你理解为什么它叫“字节对编码”。
- 从字符开始:
- 一开始,词表里只有所有基础字符(a, b, c…)。
- 统计频率:
- 扫描大量训练文本,统计哪些字符对(
Pair)出现得最频繁。
- 扫描大量训练文本,统计哪些字符对(
- 合并(Merge):
- 比如发现 ‘
d’ 和 ‘e’ 经常挨在一起,就把它们合并成一个新词元 ‘de’,加入词表。
- 比如发现 ‘
- 迭代:
- 继续统计,可能发现 ‘
de’ 和 ‘f’ 经常在一起,合并成 ‘def’- 编程领域做优化,大概率是需要单独处理
def的
- 编程领域做优化,大概率是需要单独处理
- 继续统计,可能发现 ‘
- 停止:
- 直到词表大小达到预设值(比如 GPT-2 的 50257 个)。
总结: 这一节告诉我们,现代大模型(如 GPT)不再使用简单的单词映射,而是使用 BPE。
- 好处:
- 解决了 OOV(
Out-Of-Vocabulary)问题,不再需要<|unk|>;- 压缩率高,常用词是一个 ID,生僻词是多个 ID。
- 解决了 OOV(
- 工具:
- 咱们程序员直接用
tiktoken库就行,不用手写算法
- 咱们程序员直接用
至此,文本数据的预处理工具链已经准备完毕,下一节(2.6)我们将正式开始构建用于训练的数据集(滑动窗口采样)。