高级提示工程
#2025/12/31 #ai
看完 2. 提示工程简介,你可能觉得:“这不就是把问题说清楚吗?”
但实际上,提示工程远比表面看起来复杂得多。这一节我们来看看专业高手们是怎么玩的。
目录
- 一、提示词可以有多复杂?
- 二、实战案例:论文摘要生成器
- 三、迭代实验:找到最佳提示词
- 四、上下文学习(In-Context Learning)
- 五、链式提示(Prompt Chaining) → 分解问题
- 六、常见误区与注意事项
- 七、实战建议流程
- 核心要点总结
- 最后
一、提示词可以有多复杂?
核心观点
提示词不只是三个组件(指令+数据+输出指示器),你可以根据需要构建任意复杂的提示词。
常见的高级组件
| 组件名称 | 作用 | 说明 | 举例 |
|---|---|---|---|
| 角色定位 | 告诉AI扮演什么角色 | “你是一位天体物理学专家” | |
| 指令 | 任务本身 | 指令应该尽可能具体,避免留下太大的解释空间 | |
| 上下文 | 说明任务背景 | 描述问题或任务背景的附加信息。它回答了“为什么提出这个指令”这样的问题。 | “这是为了帮助研究人员快速理解论文” |
| 格式 | 明确输出格式 | 如果不指定格式,LLM 会自行决定格式 | “用项目符号列表+一段总结” |
| 受众 | 目标读者是谁 | 比如向 5 岁的孩子解释,描述了输出的水平 | “面向忙碌的研究人员” |
| 语气 | 回答的风格 | 比如,如果你要给老板写一封正式的邮件,你肯定不想使用非正式的语气。 | “专业且清晰” |
| 数据 | 与任务本身相关的主要数据 |
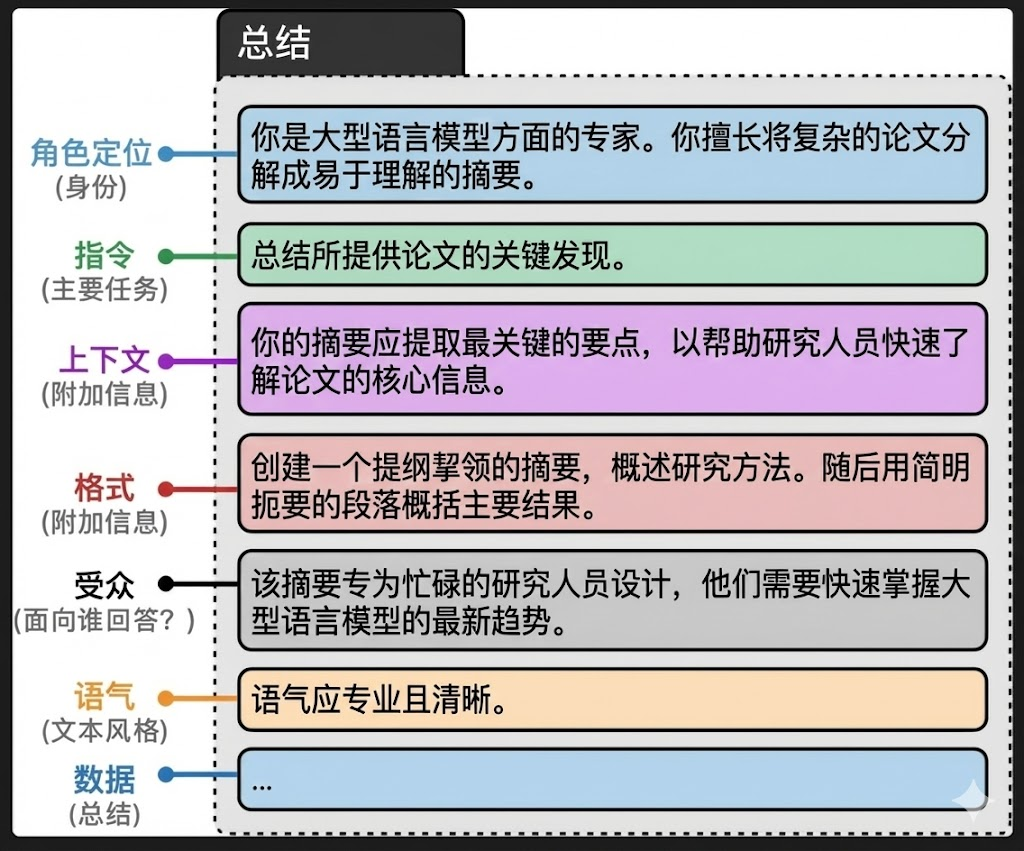
图:一个包含多个组件的复杂提示词示例
二、实战案例:论文摘要生成器
❌ 简单版
"Summarize this paper: [论文内容]"
✅ 专业版(包含所有高级组件)
# 角色定位
persona = "你是大语言模型领域的专家。你擅长将复杂的论文拆解为易于理解的摘要。\n"
# 指令(核心任务)
instruction = "总结所提供论文的关键发现。\n"
# 上下文(为什么要做这个)
context = "你的摘要应当提取最关键的要点,帮助研究人员快速理解最重要的信息。\n"
# 格式要求
data_format = "创建一个要点式摘要来概述方法。随后用简洁的段落来概括主要结果。\n"
# 目标受众
audience = "该摘要是为需要快速掌握最新趋势的忙碌研究人员设计的。\n"
# 语气
tone = "语气应当专业且清晰。\n"
# 待处理数据
data = f"待总结的文本:{text}"
# 完整提示词
query = persona + instruction + context + data_format + audience + tone + data
三、迭代实验:找到最佳提示词
核心理念
提示工程本质上是一个迭代的实验循环,没有完美的提示词,只有更适合的。
实验流程
迭代1: 指令 + 数据
↓
迭代2: + 角色定位 + 上下文
↓
迭代3: + 语气 + 受众
↓
迭代N: 调整组件顺序

图 6:对模块化组件进行迭代是提示工程的重要步骤
关键技巧
- 添加/删除组件:
- 看哪些真正有效
- 调整顺序:
- 记住首位效应和近因效应(开头和结尾最重要)
- 观察影响:
- 每次改动后都要测试输出质量
在提示工程中,我们本质上是在进行一个迭代的实验循环
四、上下文学习(In-Context Learning)
核心思想
与其描述任务,不如直接展示任务!
我们相信 “一例胜千言”,直接展示 LLM 应该实现什么以及如何实现

图 :上下文学习中使用示例的不同形式
三种形式
1. 零样本(Zero-Shot)- 不给示例
Classify the text into neutral, negative, or positive.
Text: I think the food was okay.
Sentiment:
2. 单样本(One-Shot)- 给1个示例
Classify the text into neutral, negative, or positive.
Text: I think the food was alright.
Sentiment: Neutral
Text: I think the food was okay.
Sentiment:
3. 少样本(Few-Shot)- 给多个示例
Classify the text into neutral, negative, or positive.
Text: I think the food was alright.
Sentiment: Neutral
Text: I think the food was great!
Sentiment: Positive
Text: I think the food was horrible...
Sentiment: Negative
Text: I think the food was okay.
Sentiment:
效果对比
示例越多 → 模型理解越准确 → 输出越符合预期
五、链式提示(Prompt Chaining) → 分解问题
问题场景
假设你要用AI创建一个完整的产品宣传方案,包含:
- 产品名称
- 产品口号
- 销售话术
如果一次性要求,提示词会变得非常复杂且难以控制。
解决方案:分步骤执行
第1步: [产品特征] → LLM → [产品名称]
↓
第2步: [产品特征 + 产品名称] → LLM → [产品口号]
↓
第3步: [产品特征 + 产品名称 + 口号] → LLM → [销售话术]

图 :使用产品特征描述,通过链式提示创建合适的产品名称、口号和销售宣传语
代码示例
# 步骤1:生成产品名称
product_prompt = "Create a name for a chatbot that helps with homework"
name = llm.generate(product_prompt)
# 步骤2:基于名称生成口号
slogan_prompt = f"Create a slogan for {name}"
slogan = llm.generate(slogan_prompt)
# 步骤3:基于前两步生成销售话术
pitch_prompt = f"Create a sales pitch for {name} with slogan: {slogan}"
pitch = llm.generate(pitch_prompt)
优势
✅ 每个子任务提示词更简单
✅ 可以单独调试每个步骤
✅ 模型在每个问题上投入更多 “注意力”
✅ 降低整体复杂度
应用场景
- 📖 写书:
- 概要 → 人物 → 情节 → 对话
- 🛒 购物助手:
- 理解需求 → 搜索商品 → 比较价格 → 生成清单
六、常见误区与注意事项
误区1:组件越多越好
错误思维:
- 把所有组件都加上就是最好的
正确做法: - 通过实验找到最优组合,有时候简单反而更有效
误区2:忽略组件顺序
问题:
- 中间的信息容易被“遗忘“
建议: - 重要信息放在开头或结尾
误区3:期望一次成功
现实:
- 提示工程需要反复迭代测试
心态: - 把它当作实验过程,而不是一次性任务
注意事项
- 不同模型效果不同:
- 同样的提示词在不同模型上表现差异很大
- 创意无限:
- 甚至可以加入“
情感刺激“(如”这对我的职业生涯非常重要“)
- 甚至可以加入“
- 逆向工程:
- 本质是在探索模型的学习内容和响应模式
七、实战建议流程
第一步:从基础开始
prompt = "为产品写描述"
第二步:添加核心组件
prompt = """
角色:你是一位专业的营销文案
任务:为以下产品写描述
格式:不超过两句话,正式风格
产品:[产品信息]
"""
第三步:迭代优化
- 测试不同组件组合
- 记录哪些改动有效
- 调整顺序看效果变化
第四步:复杂场景使用链式提示
# 将大任务拆解
任务1 → 输出1
↓
任务2 (使用输出1) → 输出2
↓
任务3 (使用输出1+2) → 最终结果
核心要点总结
| 概念 | 关键点 | 记忆口诀 |
|---|---|---|
| 复杂提示词 | 不限于3个组件 | 按需组合,无限可能 |
| 迭代实验 | 没有完美提示词 | 测试、观察、调整 |
| 上下文学习 | 展示胜于描述 | 一例胜千言 |
| 链式提示 | 分步骤执行 | 化繁为简,逐步推进 |
| 组件顺序 | 开头结尾最重要 | 重要信息放两端 |
最后
记住:提示工程是艺术+科学,需要创造力+系统实验!