精读:十问 Agent Skills,一场围绕 AI 编码新范式的深度研讨
#2025/12/11
https://mp.weixin.qq.com/s?__biz=Mzg2OTg5NDg3Mg==&mid=2247493421&idx=1&sn=1da1dcfec0adffc41016224ea22a0d89&scene=21&poc_token=HJCGOmmjQZGVCNTcWq-bvp1zKTTggJ5yf3xllKuk
目录
- Key Insights
- 第一问:到底什么是 Agent Skills?它和我们熟悉的 Prompt、MCP 有何本质区别?
- 第二问:既然 Skills 如此强大,它会彻底取代 MCP 吗?两者的真实关系究竟是怎样的?
- 第三问:如何设计和编写一个高质量的 Skill?有哪些最佳实践?
- 第四问:从纸上谈兵到实际应用,开发者们是如何在真实工作流中使用 Skills 的?
- 第五问:如何高效地创建和管理大量的 Skills?社区生态扮演了怎样的角色?
- 第六问:创建和调试 Skills 的具体流程是怎样的?有没有官方工具支持?
- 第七问:如何让 Claude 更“聪明”地、恰到好处地调用我们编写的 Skill?
- 第八问:在 Cursor 这样的 AI IDE 中,Skills 的管理和调用逻辑是怎样的?它和 Claude Code 有什么异同?
- 第九问:从社区分享的数据来看,Skills 主要被应用在哪些领域?呈现出怎样的发展趋势?
- 第十问:放眼未来,Skills 这条技术路线将如何演进?它对国内大模型和开发者生态有何启示?
Key Insights
一、Skills vs. MCP:客户端与服务端的路线分野
Skills更像是客户端的“插件”,强调本地执行、个性化和强可控性,适合开发者精益求精地打磨自己的专属工具链- 而 MCP 更偏向服务端的 “开放协议”,由平台方(如大厂)提供标准化的 API 体系,供广大用户调用
- 它们并非取代关系,而是互为补充,分别对应了 AI 应用开发的两种不同哲学
二、工作流的“正交性”:设计高质量 Skill 的核心原则
- 一个高质量的 Skill 设计应遵循“正交性”原则,即每个 Skill 功能单一、专注且相互独立,彼此间没有功能重叠。
- 这能让 Claude 在选择调用哪个 Skill 时毫不困惑,确保工作流的稳定与精准。
三、从 Prompt 到 Skill:开发范式的工程化演进
- Skills 的出现,标志着 AI 应用开发从“
手工作坊式”的 Prompt 编写,迈向了“工程化、可复用”的组件化时代。 - 它将指令、脚本、模板和资源文件打包管理,让 AI 的能力得以沉淀、共享和迭代。
四、社区生态的力量:claude-code-template 的启示
以 claude-code-template 为代表的开源项目,通过聚合社区贡献的 Agents、Commands、Hooks 和 Skills,极大地降低了 AI 编程的门槛,并展示了一个组件化、自动化的未来。它正努力成为 Claude Code 领域的 “Next.js”,为工程化提供了标准。
五、AI 的“记忆”难题:如何让 Claude 记住项目规范?
- 开发者们正在探索通过将项目规范、组件模板、代码结构等“记忆”封装进 Skills,来解决 AI 在大型项目中“失忆”的问题。
- 这使得 AI 能够在新任务中自动遵循项目约定,大幅提升协作效率
第一问:到底什么是 Agent Skills?它和我们熟悉的 Prompt、MCP 有何本质区别?
服务端和客户端关系
MCP好比一个由平台方提供的、标准化的“服务端”能力。- 例如,一个大型企业可能会将其内部的各种服务封装成
MCP,供客户付费使用。它是一个通用的、中转式的服务。 - 而
Skills则更像是扎根于本地的“客户端”能力。- 它允许你将自己精益求精的工作流、最佳实践封装起来,完全由自己掌控。
Skills这个词本身也很有趣,它强调“精益求精”。- 就像人人都可以买到钢琴(
MCP),但每个人的演奏水平(Skills)却千差万别。因此,Skills更加个性化,在速度、效率、准确度和自由度上有更大的发挥空间。
- 例如,一个大型企业可能会将其内部的各种服务封装成
MCP是由 Anthropic 提出的一种开放协议,旨在标准化大语言模型(LLM)与外部数据源、工具之间的交互方式。你可以把它理解为 AI 领域的“HTTP 协议”,它提供了一个通用的“插座”,让不同的 AI 模型能够以统一的方式连接到各种外部系统(如文件、数据库、API),从而获取实时、专业的上下文信息,并调用外部工具执行任务。
从商业化的角度看,一个团队或公司可以将他们宝贵的经验沉淀为一系列 Skills ,通过加入 Token 或 API 授权,让其他开发者复用,从而获得商业收益。
我也研究了 Anthropic 官方的 Skills GitHub 仓库,里面提供了十几个案例,比如自动执行 git commit 。我自己之前的 prompt 里就包含了让 AI 在完成任务后,按照专业的 Conventional Commits 风格进行 commit 的指令。现在看来,这种相对独立且标准化的任务,就非常适合剥离出来,做成一个独立的 Skill 。
这么做有两大好处:
- 分担 Context 压力 :将原本冗长的
system prompt内容移入Skill,可以减轻上下文窗口的负担。 - 增强可扩展性 :
Skill内部可以动态执行脚本和程序,能力远不止分担 Context。
所以我的判断是,对于专业的 AI 应用开发者而言, Skills 是必须要深入研究的领域。你研究得越深,开发效率和代码质量的收益就越大。当然,这也带来了新的挑战:每个 Skill 都需要单独创建文件夹和脚本,目前缺乏标准化,导致学习曲线比较陡峭,水也比较深。
伍鹏: 我补充一下。 MCP 和 Skills 的确是两个不同的东西。 MCP 是管道,而 Skill 是一个具备执行能力的终端应用 。
Skill 的一个巨大优势在于它的多端适用性。它可以在三个终端上直接使用:
- Claude Code (开发环境)
- Claude.ai (网页端直接上传)
- API 调用
这意味着 Anthropic 已经将 Skill 的能力原生植入了整个 Claude 生态。最近腾讯也加入了 Skill 这条技术路径的探索,前景非常值得期待。
从模型原理上看,所有 AI 模型基本都基于 Transformer 架构。Transformer 在执行任务时,高度依赖我们提供的指令,也就是 prompt 。但 prompt 本质上只是基于已有的输入进行文本操作,而我们大部分的真实任务,都需要和本地资源、外部世界进行交互。
这就导致了使用纯 prompt 会带来巨大的“心智切换”成本。比如,我先在 GPT 里讨论营销方案,然后需要将方案落地执行,这中间涉及到大量的工具切换和思维模式的转换。 Claude Skills 正是为了解决这个问题,它将可重复的动作抽象并打包,然后交给 Agent 去完成一整套流程,极大地减少了心智负担。
第二问:既然 Skills 如此强大,它会彻底取代 MCP 吗?两者的真实关系究竟是怎样的?
- 大厂或拥有成熟 API 体系的厂商 ,会倾向于将自身能力封装成
MCP,作为供给方提供给市场。 - 有一定研发能力的开发者或团队 ,则会更倾向于使用
Skills来满足自己高度个性化的需求。- 举个例子,以前很多人用
MCP来做爬虫,你完全可以写个脚本获取数据喂给 AI,效率更高,质量也更有保证 - 一些场景,
Skill更加易用,可复用性也更高,而MCP消耗的资源太大了
- 举个例子,以前很多人用
- 另一方面是信任问题。很多第三方的
MCP服务,你并不知道它背后具体做了什么,对其信任度不高。而Skill是我们自己搜集资源、编写脚本、自由组合的,掌控感更强。
第三问:如何设计和编写一个高质量的 Skill?有哪些最佳实践?
- 一个 Skill 要尽可能保持专注,只做好一件特定的事
- 比如,
git commit这个功能,官方就倾向于将它做成一个独立的Skill- 因为,一旦出现一个场景,Skill A 和 Skill B 都能处理,AI 就会陷入选择困难。
- 举个例子,同样是
git commit,你可以设计两个正交的 Skillgit-binary-commit: 当提交内容包含二进制文件时使用。git-text-commit: 当提交内容只包含文本文件时使用。
- 比如,
- Skill 目录层级要扁平 :
- 最多只保持一个级别,这样能确保它完整地出现在上下文中,不会因层级过深而导致信息缺失。
- 描述 (Description) 要用动词 :
- 比如,处理数据就写
processing data,提取数据就写extracting data,用现在进行时(ING 形式)来描述动作。
- 比如,处理数据就写
- 用第三方视角编写描述 :在描述整个
Skill文件时,尽可能采取客观的第三方视角。这样做能让模型在推理时,更公允地评估当前任务和将要执行的动作,减少偏差。
说 MECE 法则(相互独立,完全穷尽)
第四问:从纸上谈兵到实际应用,开发者们是如何在真实工作流中使用 Skills 的?
案例一:李不凯的“全自动微信公众号写作”工作流
我将自己写公众号的完整流程,封装成了一个专门的 Skill 。整个工作台基于 Obsidian 搭建,左侧是终端,中间是写作区,右侧是实时预览区。
当我输入一个指令,比如“请帮我写一篇关于 GPT-5.1 的公众号文章”,背后定制的 Skill 就会被激活。
整个流程大致分为三步:
- 研究与规划 :
Skill首先会调用Claude Code 内置的联网搜索功能,收集相关资料。Claude Code 自带的工具(如联网搜索、用rg做本地代码搜索)已经非常强大,甚至优于很多MCP。搜索完成后,它会生成一份内容大纲。 - 内容创作与配图 :
- 在大纲确认后,
Skill会进入创作阶段。我特别在Skill里写了一个 Python 脚本,它会自动调用Unsplash的 API 接口,抓取无版权图片并插入文章。同时,它会根据我预设的“接地气的技术布道者”文风进行写作。这个文风是通过喂给我之前写的十几篇高赞文章,让 AI 总结提炼出来的。此外,文章的样式,比如小卡片、标题格式等,也都预定义好了,AI 会自动渲染,省去了我大量排版的时间。
- 在大纲确认后,
- 审核与发布 :文章生成后,
Skill会自动进入审核环节,检查中文标点、标题与内容一致性、模板符合度等问题。最后,它会自动加上我的个人名片,我只需要点击一个按钮,就能直接推送到微信公众号的草稿箱。
这个 Skill 基本上将我过去写文章的完整流程自动化了。
案例二:橙龙的“拥有项目记忆的 Vue 组件开发”工作流
橙龙: 我在用 AI 开发 Vue 项目时,遇到了几个痛点:自定义组件复用率低、需要反复提醒 AI 参考某个页面的样式、项目代码结构不统一等。 我认为这些问题的根本原因,是 AI 缺少对这个特定项目的“记忆” 。
我的解决思路,就是通过封装组件和制定规则,并将这些“记忆”显式地写入 claude.md 或 Skill 中,来约束和指导 AI 的行为。
具体来说,我沉淀了三个层面的“记忆” Skill :
- 组件开发规范 Skill :
- 痛点 :每次新建页面,都要手动提醒 AI 使用我们团队封装好的自定义组件。
- 页面模板 Skill :
- 痛点 :不同页面的样式不统一,需要频繁提示 AI “请参考XX页面的样式”。
- 解决方案 :我整理了一个标准的“页面模板”,统一了全局样式、导航栏、视图容器和底部导航。然后将“使用此模板”的规则写入
Skill。现在,AI 在创建新页面时会自动套用模板,甚至能根据上下文判断是否需要显示底部导航栏。
- 解决方案 :我整理了一个标准的“页面模板”,统一了全局样式、导航栏、视图容器和底部导航。然后将“使用此模板”的规则写入
- 痛点 :不同页面的样式不统一,需要频繁提示 AI “请参考XX页面的样式”。
- 代码组织结构 Skill :
- 痛点 :一个组件的代码动辄上千行,维护困难,重构时需要提供大量上下文给 AI。
- 解决方案 :我将我们项目标准的组件化架构模式(如何分层、每个文件放什么)以及一些重构原则,封装成一个
Skill。当我需要重构一个巨大的文件时,只需调用这个Skill,AI 就会自动按照我们团队的最佳实践进行拆分,无需我再提供繁琐的上下文。
- 解决方案 :我将我们项目标准的组件化架构模式(如何分层、每个文件放什么)以及一些重构原则,封装成一个
- 痛点 :一个组件的代码动辄上千行,维护困难,重构时需要提供大量上下文给 AI。
李不凯: 我觉得橙龙的思路非常典型,这正是 Skill 最适合的应用场景—— 可复用的跨项目知识沉淀 。你现在将规则放在项目内的 claude.md 中,可复用性会差一些。如果把它变成一个 Skill ,那么你每开一个新的 Vue 项目,都可以直接调用它。而且,新项目中积累的经验教训,还可以反过来迭代优化这个 Skill ,让它变得越来越强大。
案例三:江流儿的“中文海报生成” Skill
江流儿整理的Skills研究文档,see: https://fcng7zbuw83t.feishu.cn/wiki/AgiVwyrS5ivQByk0ATScg0NSnfc
江流儿: 我发现 Claude 生成图片时对中文的支持很不友好。官方 Skill 库里虽然有一个 Canva 的技能,但它主要支持英文字体和布局。于是,我自己动手做了一个支持中文的图片生成 Skill 。
这个 Skill 可以很好地帮助我为微博、朋友圈、即刻等社交平台制作分享海报。它解决了中文字体、排版和布局的问题,让我可以快速生成符合中文审美的高质量图片。
第五问:如何高效地创建和管理大量的 Skills?社区生态扮演了怎样的角色?
如果让我只推荐一个搭配 Claude Code 使用的开源仓库,我绝对会选 claude-code-template 。它现在在 GitHub 上已经有 11.2k 的 Star 了。
- https://github.com/davila7/claude-code-templates
- https://www.aitmpl.com/agents
在我看来, claude-code-template 正在做一件类似于 Next.js 对 React 做的事情——它首次将 Claude Code 的工程化实践统一到了一个标准里 。
它解决的核心问题是,未来 AI 编程将从“手工拼装”时代进入“ 组件化 + 自动化 ”时代。这个仓库就像一个巨大的“武器库”或者“商城”,你可以进去挑选你需要的各种组件,一键安装到你的工作流里。
我自己的工作流通常是这样:
- 安装 CLI :通过
npx claude-code-template@latest命令安装。 - 项目初始化 :使用它内置的项目模板(如 React, Node.js, Python)快速生成项目骨架,它会自动帮你配置好项目结构、默认组件和 SDK。
- 挑选组件 :去它的线上市场挑选我需要的 Agents、Commands 或者 Skills,比如我今天的 PPT 就是用它提供的一个
pptxSkill,只花十分钟就做出来了。 - 使用工具链 :它还提供了一套强大的工具链。我最喜欢的是它的“分析仪表盘”和“健康检查”功能。
- 分析仪表盘 :它能读取你本地 Claude Code 的所有运行数据,生成一个可视化的 Web 界面,你甚至可以在手机上实时监控 AI 的工作进展。
- 健康检查 :每次启动一个新项目,我都会用它来检查项目的验证状态、兼容性、环境依赖和版本问题。
claude-code-template 的哲学是,它不是一个人闭门造车,而是鼓励全世界的工程师把遇到的问题用代码解决,然后开源共享。如果你写了一个很棒的 Skill ,可以直接提交到这个仓库,与全球的开发者分享。
南川: lords 的分享非常有启发。这个项目让我看到了一个有趣的商业化可能性:做一个“GitHub 深度研究”的 SaaS。比如,当你想研究一个新的技术领域,如“笔记软件”,你在这个 SaaS 里输入关键词,它会自动去 GitHub 爬取所有相关的开源项目,按照 star 数、技术栈、功能特性等维度进行分析、排名,并生成一份详尽的研究报告。这本质上也是一种 template 或 Skill 的思想。
第六问:创建和调试 Skills 的具体流程是怎样的?有没有官方工具支持?
- Anthropic 官方代码库里其实提供了一个名为
skill-creator的Skill。它就是一个“Skill 生成器”,你可以用它来创建新的Skill。这是一种“元编程”的思路,用Skill来生成Skill,生成的Skill质量通常不会差。 - https://github.com/anthropics/skills
一个标准的 Skill 文件夹结构包含:
SKILL.md: 核心文件,用 YAML Frontmatter 定义name和description,正文是给 Claude 的指令。meta文件: 元数据。resources文件夹: 存放各种资源,如脚本 (scripts)、参考材料 (references)、模板等。
李不凯: 我目前创建的十个 Skill 基本都是用官方的 skill-creator 写出来的。
至于调试,我的方法是一种 自我循环、持续迭代 的模式:
- 在实际任务中使用一个
Skill。 - 发现它在某个环节做得不好,或者出错了。
- 立即调用
skill-creator这个Skill,告诉它刚才遇到了什么问题,让它来修改原来的Skill。 - 修改后,在下一个任务中继续使用,观察效果。
通过这样不断的“ 使用 -> 发现问题 -> 调用元 Skill 修正 -> 再使用 ”的循环, Skill 的能力会变得越来越好,越来越贴合你的需求。
陈涵洋: 我在使用 Skill 时发现一个痛点,就是 断点调试能力非常差 。如果 Skill 写错了,在错误发生时你几乎没有什么挽回措施。不知道大家有没有什么好的尝试?
李不凯: 这确实是一个问题,目前的调试主要还是依赖于我上面说的那种“事后复盘、迭代优化”的模式,缺乏实时的断点调试能力。
第七问:如何让 Claude 更“聪明”地、恰到好处地调用我们编写的 Skill?
- 问题:
- Claude 无法精准地判断用户的意图,导致该调用
Skill的时候没调用,或者调用了错误的Skill
- Claude 无法精准地判断用户的意图,导致该调用
- 解决方案:
- ① 为了解决这个问题,我尝试了一个方法,就是在系统级的
claude.md文件里,把所有我创建的Skill的名称和它们对应的触发关键词都明确地列出来。这么做之后,我感觉调用的成功率大概提升了一到两倍 - ② 模型在匹配规则时,是根据
语义相似度来实现的。它会计算你的指令和每个Skill描述之间的“蕴含关系”。比如,当你的指令是“烹饪”,模型就会去寻找与“炊具”、“食材”、“烹饪方法”等概念相关的Skill。- 所以,需要尽量保证每个 skill 的描述都是相互独立的,避免在场景上产生混淆,这是提升调用准确率的根本 。
- ③ 光靠
description有时候是不够的。AI 对于“什么时候用”甚至“什么时候不用”的理解,还不够精确。- 最佳实践是,在
Skill的.md文件里, 明确地用自然语言告诉它 :- “在 A、B、C 场景下,你必须使用这个 Skill”
- “在 X、Y、Z 情况下,你绝对不能用这个 Skill”。
- 这种类似
SOP(Standard Operating Procedure) 的强约束,效果非常显著。
- 最佳实践是,在
- ① 为了解决这个问题,我尝试了一个方法,就是在系统级的
第八问:在 Cursor 这样的 AI IDE 中,Skills 的管理和调用逻辑是怎样的?它和 Claude Code 有什么异同?
Cursor在规则管理上有一个优势,就是它提供了一套分层、分级的规则调用机制 。- 在
Cursor的设置里,你可以添加规则 (Rules),并且为每条规则指定生效的条件:- 始终有效 (Always) :在任何对话中都会启用。
- AI 决定 (Agent Decides) :由 Agent 自行判断当前对话是否与该规则相关。
- 文件匹配 (On File Match) :当对话涉及到匹配特定文件(如
*.vue)时才生效。 - 手动触发 (Always Manually) :只有当你手动
@它的时候才会生效。
- 在
Claude Code目前似乎缺少这种精细化的规则管理机制。- 比如,当一个场景下有多个
Skill可能都适用时,如果能有一个机制让我手动指定本次对话强制使用某一个Skill,而不是让 AI 自己去猜,会大大增强可控性。 - 关于你提到的工作流编排问题,可以关注一下一个名为
Claude Flow的库。- 我看到在很多开源的
Skill实现中,都使用了这个库来对任务进行编排,掌控整个流程的执行顺序。
- 我看到在很多开源的
- 比如,当一个场景下有多个
第九问:从社区分享的数据来看,Skills 主要被应用在哪些领域?呈现出怎样的发展趋势?
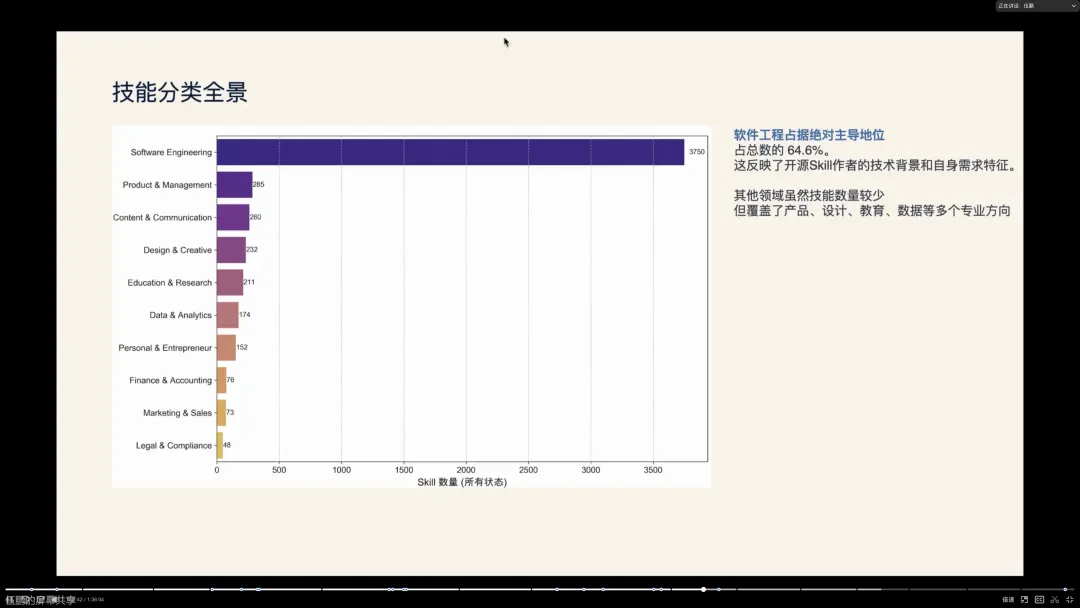
伍鹏: 我在上个月做了一个 Skill 网站,因此收集并分析了 GitHub 上近 5800 个开源的 Skill 仓库数据,有一些有趣的发现:
- 软件工程领域占据绝对主导 :
- 在所有
Skill中,有超过 3750 个与软件工程相关,占比极高。这反映了目前Skill的主要创建者和使用者仍然是开发者群体。
- 在所有
- “自动化”是核心诉求 :
- 在所有
Skill的关键词中,“自动化 (automation)”出现了 1180 次,平均每五个Skill就有一个与自动化强相关。这说明,大家使用Skill的最主要目的,就是将重复性的工作自动化,比如每天编写文档、计算 Excel 表格、处理财务数据等。
- 在所有
- 社区想象力远超官方 :
- 官方仓库提供的
Skill更多是作为示例,或者对自己已有产品在新路径上的适配。而社区贡献的Skill则展现出了更丰富的多样性和想象力,涵盖了各种意想不到的组合和可能性。
- 官方仓库提供的
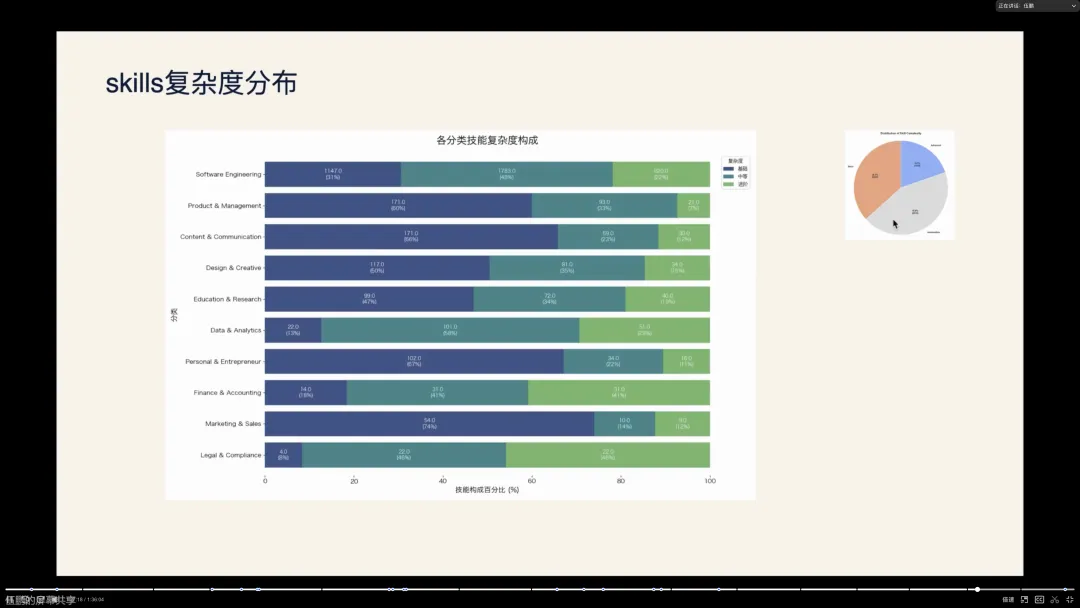
- 复杂度分布 :
- 高阶 Skill (占比最小) :拥有多种复杂能力组合,通常包含多个脚本和引用文件。
- 中阶 Skill (占比接近一半) :具备简单的引用文件,可能包含脚本。
- 初阶 Skill (占比较多) :只有一个
SKILL.md文件,不含脚本,纯粹是模型能力的调用。
- 高阶 Skill (占比最小) :拥有多种复杂能力组合,通常包含多个脚本和引用文件。
- 技术栈偏好 :
- 在需要编写脚本的
Skill中,创作者们普遍倾向于使用那些排名靠前、成熟且活跃的库,比如git,pandas以及前面提到的claude-flow。大家更愿意使用经过验证的“轮子”,而不是重复发明。
- 在需要编写脚本的
第十问:放眼未来,Skills 这条技术路线将如何演进?它对国内大模型和开发者生态有何启示?
Skill 这套机制非常依赖 Claude 自身模型的针对性微调,如果换成国内的模型,效果可能会大打折扣?
- 这本质上考验的是大模型对
SOP(标准作业程序) 这类语义的理解与严格遵循的能力 。这种能力本身应该是通用的,微调也许有用,但作用可能非常小。
我把我的“微信公众号写作” Skill 分别用三个模型跑了一遍:
- Claude 4.5: 基本能 100% 完美地按照我的指令执行下来,非常顺畅。
- Kimi: 大概能完成 85% 到 90% 的任务。
- 豆包: 大概只能完成 60% 左右。
我个人的感觉是, Skill 这套理念和技术实现,其核心是简单和通用的,这也是它最大的价值所在。所以,切换到别的模型上,重点还是考验模型本身对于 指令遵循 (Instruction Following) 的能力。像 Kimi,它的指令遵循能力也很好,所以实现的效果和 Claude 就很接近。而豆包可能在这方面能力稍弱,所以效果打了折扣。
因此,我非常看好 Skill 能够成为一个业内通用的标准,未来在各个模型和 IDE 中都能得到很好的支持。
Agent Skills背后的巨大潜力与现实挑战。它不仅是一个新工具,更像是一个新的“思想容器”,让我们可以将抽象的知识、重复的流程、宝贵的经验,固化成可调用、可组合、可迭代的 AI “能力单元”。
从 Prompt 到 Skill ,从 MCP 的外部调用到 Skill 的本地深耕, 我们正处在一个 AI 开发范式剧烈变革的时代 。
未来,每一位开发者或许都将拥有一个属于自己的、不断进化的“技能库”,而衡量一个开发者能力的,除了代码本身,或许还要看他“教会”了 AI 多少独特的 Skills 。
这场对话只是一个开始,我们期待看到更多开发者加入到 Skills 的探索与创造中来,共同塑造 AI Native 开发的未来。