新增了一个工具:
load_skill
原因
- Agent 需要遵守项目规则,但不能把所有规则都提前塞进
system prompt。 - 当前仓库里已经有项目级 skill:
course-blogsync-upstream
- 这些 skill 本质上是项目 SOP。
- 工具负责“能做什么动作”。
- skill 负责“什么时候、按什么流程做动作”。
- 如果一启动就把每个
SKILL.md全塞给模型,后果很直接:- 每一轮请求都带一堆当前任务用不上的规则。
- system prompt 越来越长。
- 真正重要的用户任务反而被挤远。
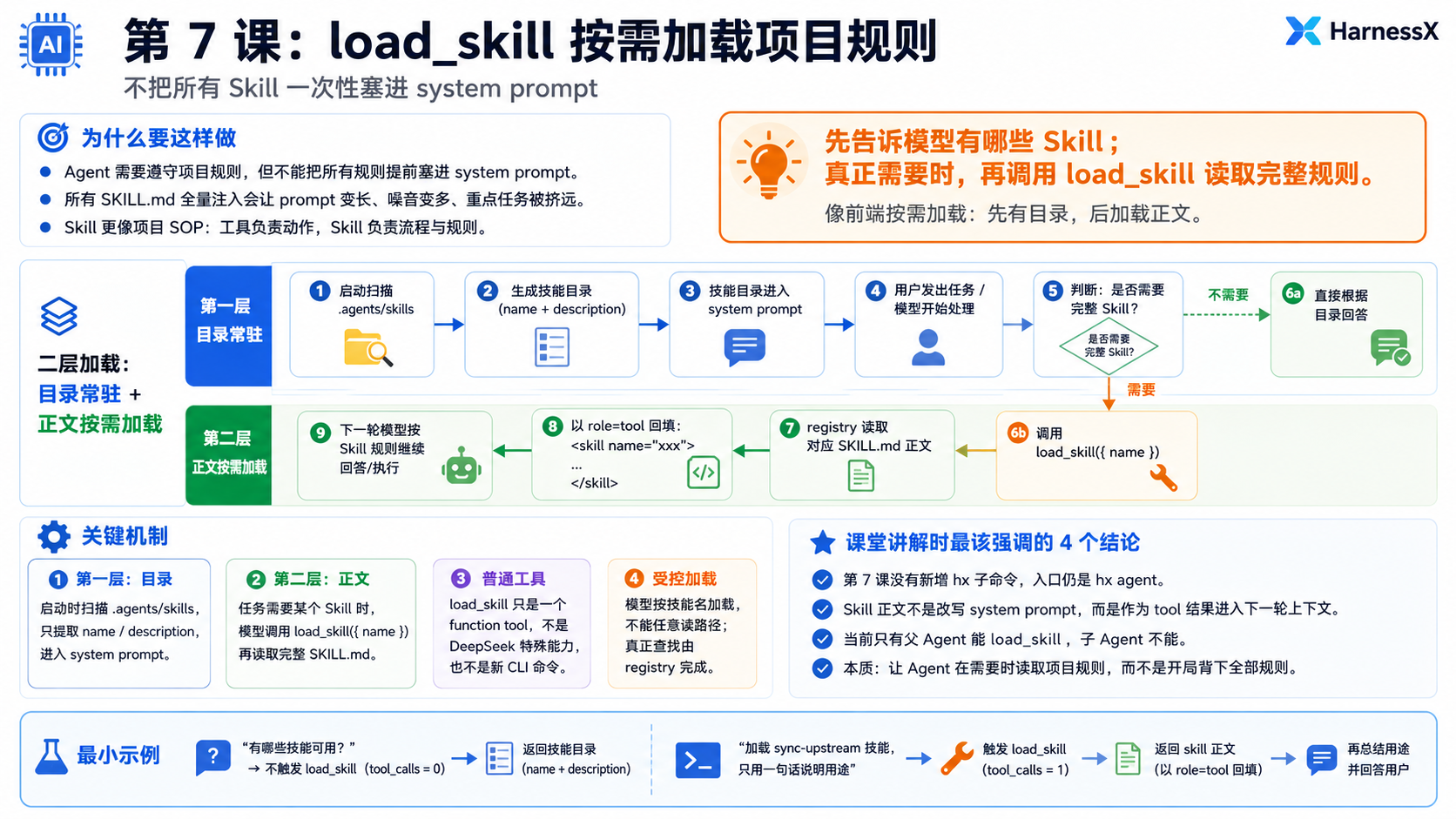
- 第 7 课当前要做的是
按需加载:- 启动时只告诉模型“有哪些 skill”。
- 需要完整规则时,模型再调用
load_skill。 load_skill把某个SKILL.md正文作为工具结果回填给下一轮模型。
一句话:
Skills 不是让 Agent 多一个执行动作,而是让 Agent 在需要时再读取项目规则。这个机制很像前端的按需加载。
- 前端不会在首屏把所有页面组件都打进一个巨大 bundle。
- 首屏先知道有哪些路由、菜单和入口。
- 用户真的点进某个页面时,再加载那个页面的 chunk。
load_skill做的是同一类事。system prompt先放技能目录。- 用户任务真的需要某个技能时,再把对应
SKILL.md正文加载进当前对话。
重点
- 第 7 课没有新增
hx子命令。- 用户还是敲
hx agent "..."。 - 第 7 课只是给 Agent Loop 多一个
工具:load_skill。
- 用户还是敲
- 第 7 课新增的是两层加载:
- 第一层是目录。
- 程序启动时扫描
.agents/skills。 - 只取
name和description。 - 这部分进入
system prompt,每轮都在。
- 程序启动时扫描
- 第二层是正文。
- 模型需要某个技能的完整规则时,调用
load_skill({ name })。 - 程序从
registry里取出对应SKILL.md正文。 - 正文作为
role: "tool"回填给下一轮模型。
- 模型需要某个技能的完整规则时,调用
- 第一层是目录。
- 当前实现只服务父 Agent。
- 子 Agent 仍然只拿
bash/read_file/write_file/edit_file/glob。 - 子 Agent 没有
load_skill。 - 这是为了让第 7 课先把一件事讲清楚:
- 父 Agent 怎么按需加载项目规则。
- 子 Agent 仍然只拿
流程图
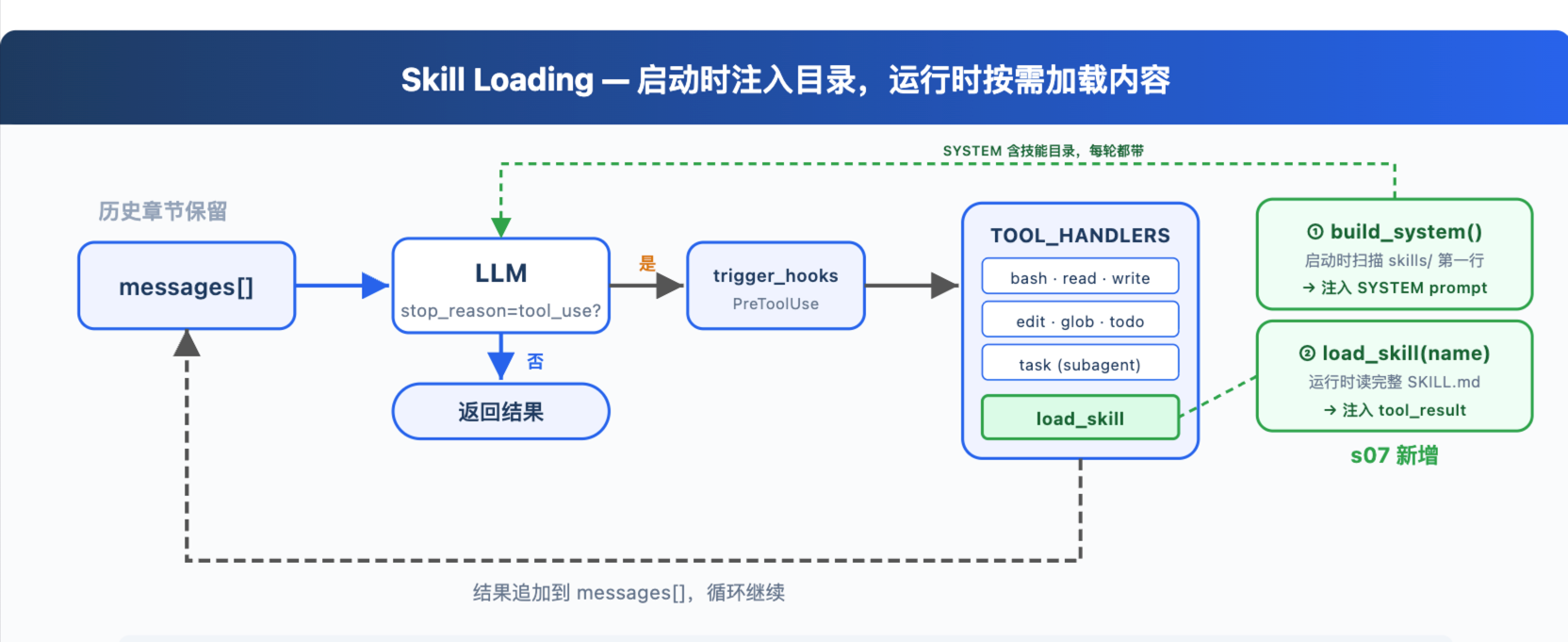
总流程

这个图要看懂两点:
system prompt里只有目录,不是完整 skill。- 完整
SKILL.md是模型主动调用load_skill后才进入messages。
HTTP 一来一回

这里的关键是:
load_skill不是 DeepSeek API 的特殊字段。- 它只是一个普通 function tool。
- DeepSeek 返回
tool_calls。 - 本地程序执行
runLoadSkill。 - 执行结果仍然按普通工具结果回填。
入口
第 7 课没有新增命令。
hx agent "加载 sync-upstream 技能,只用一句话说明它的用途,不要执行同步"入口仍然在 src/index.js:
if (command === "agent") {
// 第 7 课:load_skill 加到 Agent Loop 里,agent 入口仍然不变。
const task = rest.join(" ").trim();
await runAgent(task);
return;
}src/index.js不关心 skill 怎么扫描。src/index.js只把用户任务交给runAgent。load_skill是 Agent Loop 里的工具,不是一个新 CLI 命令。
第一层:启动时只注入技能目录
第 7 课启动时会先加载 skill registry:
const DEFAULT_SKILLS_DIR = ".agents/skills";
const SKILL_REGISTRY = loadSkillRegistry();这一步做的事很少:
- 从当前目录向上找
.agents/skills。 - 递归找所有
SKILL.md。 - 解析最简单的
frontmatter。 - 得到
name和description。
当前仓库能得到这类目录:
- course-blog: 为 HarnessX 当前课程生成一篇个人博客草稿。
- sync-upstream: Use inside 832X when the user invokes /sync-upstream, 同步上游, or sync upstream to update the learn-claude-code reference.然后目录进入父 Agent 的 system prompt:
const SYSTEM_PROMPT = [
`你是运行在 ${process.cwd()} 的编程 Agent。`,
"请使用工具完成用户任务。",
// 目录只告诉模型“有哪些技能”,不提前给完整正文。
"可用技能目录如下,目录只包含技能名和一句描述:",
SKILL_REGISTRY.listDescriptions(),
// 如果任务真的需要某个技能,再让模型调用 load_skill。
"如果用户询问有哪些技能,可以先根据目录回答。",
"如果用户点名某个技能、命令入口、项目工作流,或任务需要遵循特定项目规则,先调用 load_skill 加载完整说明,再继续执行。",
"load_skill 只加载 SKILL.md 指令,不会执行里面的命令。",
].join("\n");这就是第一层。
便宜目录:每轮都带
完整正文:用到再加载换成前端的话就是:
路由表 / 菜单名:首屏就有
页面 chunk:点进页面再加载
skill 目录:启动时就有
SKILL.md 正文:调用 load_skill 再加载第二层:运行时调用 load_skill
第 7 课给 DeepSeek 多发了一个工具定义:
{
type: "function",
function: {
name: "load_skill",
description: "按名称加载项目级 skill 的完整说明。",
parameters: {
type: "object",
properties: {
name: {
type: "string",
description: "要加载的技能名,例如 sync-upstream。",
},
},
required: ["name"],
},
},
}模型看到用户说“加载 sync-upstream 技能”,就可以返回这样的工具调用:
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"type": "function",
"function": {
"name": "load_skill",
"arguments": "{\"name\":\"sync-upstream\"}"
}
}
]
}本地还是走同一张工具分发表:
const TOOL_HANDLERS = {
bash: runBashTool,
read_file: runReadFile,
write_file: runWriteFile,
edit_file: runEditFile,
glob: runGlob,
todo_write: runTodoWrite,
task: runTaskTool,
load_skill: runLoadSkill,
};这就是第 2 课工具分发的延续。
- 第 2 课讲的是:
- 工具名进来,用
TOOL_HANDLERS[toolName]找本地函数。
- 工具名进来,用
- 第 7 课只是多了一项:
load_skill: runLoadSkill。 - Agent Loop 不需要为 skill 写一条特殊分支。
- 是的,先实现就好
load_skill 真正做了什么
load_skill 不接收文件路径。
function runLoadSkill(input) {
const name = typeof input.name === "string" ? input.name.trim() : "";
if (!name) {
return "Error: load_skill.name must be a non-empty string";
}
return SKILL_REGISTRY.load(name);
}这点很重要。
- 模型不能说 “读取任意路径”。
- 模型只能说 “加载某个已登记的技能名”。
- 真正的查找发生在 registry 里。
registry 成功时返回:
<skill name="sync-upstream">
# /sync-upstream
## 使用场景
用户在 832X 中输入 `/sync-upstream`、`同步上游` 或 `sync upstream` 时使用。
...
</skill>这里包一层
<skill name="...">...</skill>,是为了给模型一个明确边界:这段内容是被加载进来的 skill 正文,不是普通工具输出,也不是用户新输入。它同时标记来源、范围和名称。重点不是 XML,而是把加载出来的规则包成一个可识别的上下文块。
失败时返回:
Error: unknown skill xxx. Available: course-blog, sync-upstream这不是权限系统,也不是插件系统。
它只是一个受控的项目规则加载器。
这个工具结果怎么进下一轮模型
load_skill 和其他工具一样,最终都会回填到 messages:
const output = await runToolCall(toolCall, stats);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: output,
});如果这次 output 是 sync-upstream 的技能正文,下一轮模型看到的就是:
{
"role": "tool",
"tool_call_id": "call_xxx",
"content": "<skill name=\"sync-upstream\">...</skill>"
}所以第 7 课真正新增的链路是:
技能目录进 system prompt
-> 模型决定是否需要完整技能
-> tool_calls: load_skill
-> runLoadSkill 返回 <skill>正文</skill>
-> role=tool 回填
-> 下一轮模型按技能规则继续子代理为什么不拿 load_skill
当前子代理工具列表还是这 5 个:
const SUBAGENT_TOOL_NAMES = new Set([
"bash",
"read_file",
"write_file",
"edit_file",
"glob",
]);也就是说:
- 父 Agent 可以调用
load_skill。 - 子 Agent 不可以调用
load_skill。 - 子 Agent 也没有
todo_write和task。
这是当前课的边界。
第 6 课已经讲过子代理:子代理负责局部探索,最终只把结论交回父 Agent。
第 7 课只讲父 Agent 怎么按需加载项目规则。先不要把“子代理也能加载技能”放进来,否则这一课会多一层心智负担。
怎么跑

沿用第 0 课的 npm link 和 DeepSeek 配置,这里只跑第 7 课的最小完整示例。
先问有哪些 skill:
hx agent "有哪些技能可用?只列名称,不要加载完整技能"这条命令能触发第一层能力:
- 模型只看
system prompt里的技能目录。 - 不需要调用
load_skill。
实际输出里可以看到没有工具调用:
[HOOK] UserPromptSubmit cwd=/Users/liguwe/832/832X
[HOOK] Stop: turns=1, tool_calls=0, blocked=0
当前可用的技能有:
1. course-blog
2. sync-upstream再明确加载一个 skill:
hx agent "加载 sync-upstream 技能,只用一句话说明它的用途,不要执行同步"这条命令能触发第二层能力:
- 用户点名
sync-upstream。 - 模型调用
load_skill。 - 程序把
sync-upstream的完整正文回填给模型。 - 模型再按 skill 正文总结用途。
关键输出:
[HOOK] UserPromptSubmit cwd=/Users/liguwe/832/832X
> load_skill name=sync-upstream
[HOOK] PreToolUse load_skill({"name":"sync-upstream"})
[HOOK] PostToolUse load_skill output_chars=833
<skill name="sync-upstream">
# /sync-upstream
...
[HOOK] Stop: turns=2, tool_calls=1, blocked=0
sync-upstream 技能用于将 832X 仓库中的 references/learn-claude-code 子模块同步到上游最新版本,不提交、不推送。判断跑通只看三件事:
- 问技能列表时,
tool_calls=0。 - 加载
sync-upstream时,终端出现> load_skill name=sync-upstream。 - 最终回答基于
sync-upstream的正文,而不是瞎猜。
这一课真正要记住
Skill:- 一个项目规则文件,当前就是
.agents/skills/<name>/SKILL.md。
- 一个项目规则文件,当前就是
skill catalog:- 技能目录,只包含
name和description,放进system prompt。
- 技能目录,只包含
load_skill:- 一个普通工具,按技能名加载完整
SKILL.md正文。
- 一个普通工具,按技能名加载完整
role=tool:- 技能正文不是直接改 system prompt,而是作为工具结果进入下一轮上下文。
父 Agent:- 当前唯一能加载 skill 的 Agent。
子 Agent:- 仍然只做局部探索,不加载 skill。
第 7 课的一句话:
先让模型知道有哪些技能;等它真的需要某个技能时,再用 load_skill 把完整规则放进当前对话。源码
这里保留当前版本的主流程缩略代码,方便以后代码继续往后迭代时,还能回来看第 7 课到底加了什么。
代码概览
src/index.js 仍然只负责命令入口:
if (command === "agent") {
// 第 7 课没有新增子命令。
// load_skill 是 agent 内部工具。
const task = rest.join(" ").trim();
await runAgent(task);
return;
}src/agent-loop.js 启动时先准备 skill registry:
const DEFAULT_SKILLS_DIR = ".agents/skills";
const SKILL_REGISTRY = loadSkillRegistry();父 Agent 的 system prompt 只放目录:
const SYSTEM_PROMPT = [
`你是运行在 ${process.cwd()} 的编程 Agent。`,
"可用技能目录如下,目录只包含技能名和一句描述:",
SKILL_REGISTRY.listDescriptions(),
"如果用户点名某个技能、命令入口、项目工作流,或任务需要遵循特定项目规则,先调用 load_skill 加载完整说明,再继续执行。",
].join("\n");工具分发表多了 load_skill:
const TOOL_HANDLERS = {
bash: runBashTool,
read_file: runReadFile,
write_file: runWriteFile,
edit_file: runEditFile,
glob: runGlob,
todo_write: runTodoWrite,
task: runTaskTool,
load_skill: runLoadSkill,
};代码细分
loadSkillRegistry 负责扫描 .agents/skills:
function loadSkillRegistry({ cwd = process.cwd(), skillsDir = ".agents/skills" } = {}) {
const { workspaceRoot, skillsRoot } = resolveSkillsRoot(cwd, skillsDir);
const skills = [];
if (skillsRoot) {
for (const skillPath of findSkillFiles(skillsRoot)) {
const raw = readFileSync(skillPath, "utf8");
const { meta, body } = parseSkillMarkdown(raw);
// name 和 description 是目录层信息。
// body 是完整正文,只有 load_skill 被调用时才返回。
skills.push({
name: meta.name || path.basename(path.dirname(skillPath)),
description: meta.description,
body,
relativePath: path.relative(workspaceRoot, skillPath),
});
}
}
return createSkillRegistry(skills);
}resolveSkillsRoot 从当前目录向上找 .agents/skills:
function resolveSkillsRoot(cwd, skillsDir) {
let current = path.resolve(cwd);
while (true) {
const candidate = path.join(current, skillsDir);
if (existsSync(candidate)) {
return { workspaceRoot: current, skillsRoot: candidate };
}
const parent = path.dirname(current);
if (parent === current) {
return { workspaceRoot: path.resolve(cwd), skillsRoot: null };
}
current = parent;
}
}parseSkillMarkdown 只解析当前课需要的简单 frontmatter:
function parseSkillMarkdown(text) {
if (!text.startsWith("---\n")) {
return { meta: {}, body: text.trim() };
}
const end = text.indexOf("\n---", 4);
if (end === -1) {
return { meta: {}, body: text.trim() };
}
return {
meta: parseSimpleFrontmatter(text.slice(4, end)),
body: text.slice(end + 4).trim(),
};
}createSkillRegistry 对外暴露两件事:
function createSkillRegistry(skills) {
const byName = new Map();
for (const skill of skills) {
byName.set(skill.name, skill);
}
return {
// 给 system prompt 用:只返回轻量目录。
listDescriptions() {
return skills.map((skill) => `- ${skill.name}: ${skill.description}`).join("\n");
},
// 给 load_skill 用:只允许按已登记名称加载正文。
load(name) {
const skill = byName.get(name.trim());
if (!skill) {
return `Error: unknown skill ${name}`;
}
return `<skill name="${skill.name}">\n${skill.body}\n</skill>`;
},
};
}使用
<skill>为了更结构化,更好识别
runLoadSkill 是工具入口:
function runLoadSkill(input) {
const name = typeof input.name === "string" ? input.name.trim() : "";
if (!name) {
return "Error: load_skill.name must be a non-empty string";
}
return SKILL_REGISTRY.load(name);
}最后仍然走原来的工具回填:
const output = await runToolCall(toolCall, stats);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: output,
});所以第 7 课没有推翻前面的课。
它只是把前面几课串起来:
第 2 课:工具分发表
第 4 课:工具前后触发 hooks
第 6 课:子代理保持工具边界
第 7 课:把项目规则做成可按需加载的 skill最后收束成这条主链路:
.agents/skills -> skill catalog -> system prompt -> load_skill -> role=tool -> 下一轮模型