新增了一个工具:
compact
原因
- Agent 手里有
bash、read_file、write_file,能力是够的。 - 但它读了一个 1000 行文件,又读了 30 个文件,跑了 20 条命令。
- 每条命令的输出、每个文件的内容,全都堆在
messages里。 - 上下文窗口是有限的。满了之后,API 直接拒绝:
prompt_too_long。 - 不压缩,Agent 根本没法在大项目里干活。
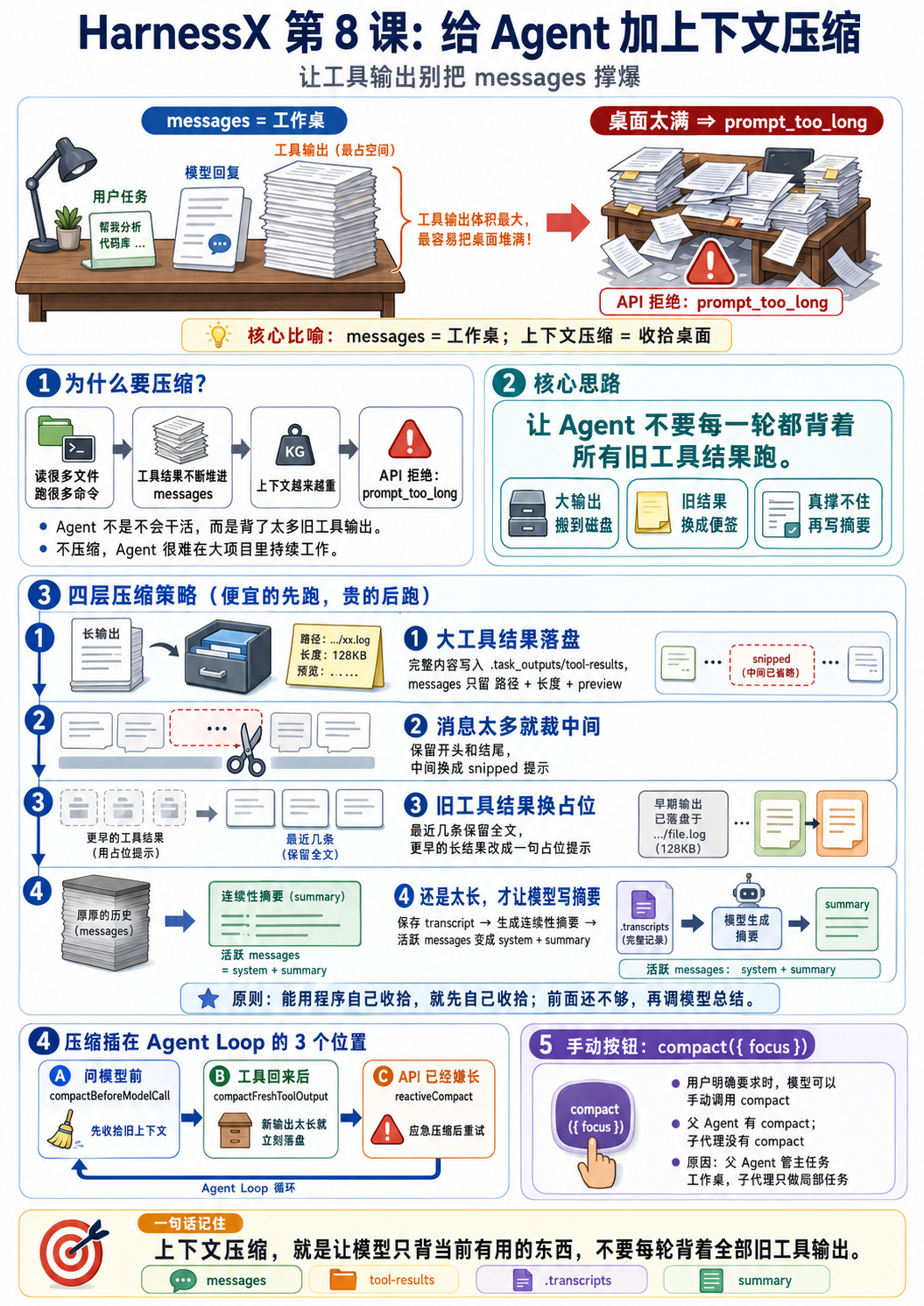
这一课解决的就是这个问题:
让 Agent 不要每一轮都背着所有旧工具结果跑。这一课先记住什么
messages就像模型的工作桌。- 用户任务在桌上。
- 模型回复在桌上。
- 工具结果也在桌上。
- 工具结果最容易把桌面堆满。
- 一个长文件就是几万字符。
- 多读几个文件,下一轮请求就很重。
- 上下文压缩就是收拾桌面。
- 大文件输出搬到磁盘。
- 旧工具结果换成一句提示。
- 整段历史太长时,压成一份继续干活用的摘要。
第 8 课不是新增一个更聪明的模型。
第 8 课是给 Agent Loop 加一个习惯:
每次找模型前,先看一眼 messages 还放不放得下。先看人话流程图

先别背函数名。
这一课先记住一个画面:
messages 是桌面。
工具结果是最占地方的纸。
上下文压缩就是收拾桌面。四层压缩策略:便宜的先跑,贵的后跑
这节最容易被函数名绕晕。先看这张图

先基于一个具体任务看:
# 用户让 Agent 做一个很常见的项目阅读任务:
hx agent "读取 README.md、src/agent-loop.js 和 references/learn-claude-code/s08_context_compact/README.md,然后总结第 8 课上下文压缩怎么做"这个任务会发生什么?
- Agent 会读文件。
- 每次
read_file的结果都会作为role=tool放进messages。 - 如果文件很长,
messages很快就会变重。
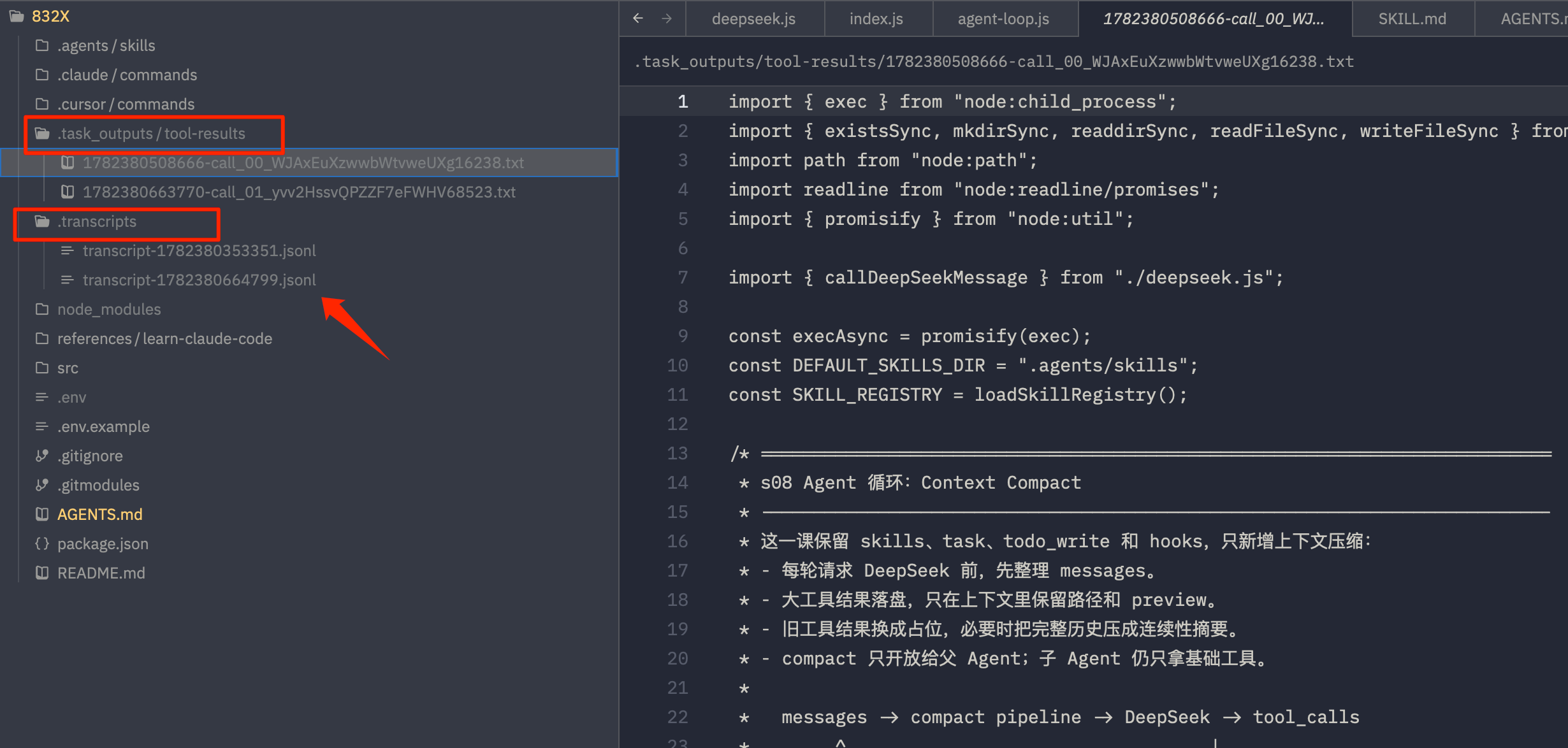
看看我本地代码最终文件夹里有什么,如图
所以第 8 课的策略是:
先用 Node.js 自己能做的办法收拾。
这些办法都不需要再问模型,所以便宜。
还放不下时,再请 DeepSeek 写摘要。
摘要需要再调一次模型,所以贵。把它画成一张“同一个任务怎么被四层处理”的图:

四层分别看:
- 第一层:大工具结果落盘。
- 触发方式:某个工具输出太长,或者工具结果总量太大。
- 完整内容存到哪里:
.task_outputs/tool-results/xxx.txt。 messages里剩什么:一张便签,写着文件路径、原始长度、前 2000 字符预览。
原来 messages 里是:
README 全文 + agent-loop.js 全文 + 参考教程全文
第一层之后 messages 里变成:
<persisted-output>
Full output saved to: .task_outputs/tool-results/xxx.txt
Original length: 42255 chars
Preview:
前 2000 个字符...
</persisted-output>- 第二层:消息太多就裁中间。
- 触发方式:
messages条数超过阈值。 - 完整内容存到哪里:不新增文件。
messages里剩什么:开头保留,结尾保留,中间换成一句“这里裁掉了多少条消息”。
- 触发方式:
原来 messages 是:
system -> user -> assistant -> tool -> assistant -> tool -> ... -> 最新 tool
第二层之后 messages 变成:
system -> user -> [snipped 32 messages from conversation middle] -> 最新几条消息- 第三层:旧工具结果换便签。
- 触发方式:工具结果太多,只保留最近几条全文。
- 完整内容存到哪里:不新增文件。
messages里剩什么:最近 3 条工具结果保留全文,更早的长工具结果换成占位提示。
# 旧工具结果已经不放全文了,只留一句提醒:
[Earlier tool result compacted. tool_call_id=call_abc. Re-run the tool if the full output is needed.]- 第四层:生成连续性摘要。
- 触发方式:前三层都跑完后,整体上下文还是超过阈值。
- 完整内容存到哪里:
.transcripts/transcript-xxx.jsonl。 messages里剩什么:原来的长历史被替换成system + continuity summary。
原来 messages 里有很多轮对话和工具结果。
第四层之后 messages 只保留:
system:
你是运行在当前目录的编程 Agent...
user:
[Conversation compacted by HarnessX. reason=auto]
Transcript archive: .transcripts/transcript-xxx.jsonl
Continuity summary:
当前任务是总结第 8 课上下文压缩。
已经读取 README、src/agent-loop.js 和参考教程。
关键结论是:工具结果先落盘,旧结果换便签,历史太长再摘要。
下一步应该继续基于摘要回答用户。对应到函数名,其实就是这个顺序:
async function compactBeforeModelCall(messages, stats) {
// 第一层:大输出搬走,桌面只留便签。
toolResultBudget(messages);
// 第二层:消息条数太多,裁掉中间一段。
snipCompact(messages);
// 第三层:旧工具结果换成一句占位提示。
microCompact(messages);
// 第四层:前面三层还不够,再请 DeepSeek 写摘要。
if (estimateContextSize(messages) > CONTEXT_COMPACT_THRESHOLD) {
await compactHistory(messages, { reason: "auto", stats });
}
}还有一个 reactiveCompact,它更像急救箱:
前面几层已经跑过了。
API 还是返回 prompt_too_long。
这时保存 transcript,再生成摘要,最后重试一次。图一:为什么会满

Agent 卡住,不是因为它不会读文件。
它是因为读过的东西都在 messages 里,下一轮还要继续带着。
图二:大输出搬到磁盘

这一步最像收拾桌面:
- 完整文件还在。
- 只是从桌面搬到抽屉。
- 桌面只留一张便签。
便签长这样:
<persisted-output>
Full output saved to: .task_outputs/tool-results/xxx.txt
Original length: 42255 chars
Preview:
前 2000 个字符...
</persisted-output>对应代码只看这一行就够:
content: compactFreshToolOutput(toolCall.id, output),工具结果回填前,先判断要不要搬走。
图三:旧结果换成占位

旧工具结果不一定要一直全文保留。
比如 Agent 已经读了 10 个文件,前 7 个文件只是帮它完成了中间判断。下一轮继续带着全文,通常只是占位置。
所以旧结果会变成:
# 这不是完整工具结果,只是一句占位提示:
# 早一点的工具结果已经被压缩;如果后面还需要全文,就重新跑工具。
[Earlier tool result compacted. Re-run the tool if the full output is needed.]这句话的意思很直白:
这里以前有结果。
现在先不带全文。
真要用,再读一次。图四:每次找模型前先收拾

这就是 compactBeforeModelCall():
await compactBeforeModelCall(messages, stats);
const message = await callDeepSeekMessage(messages, {
tools: TOOL_DEFINITIONS,
tool_choice: "auto",
});这里不要被 toolResultBudget、snipCompact、microCompact 这些名字吓住。
先做不花钱的整理。
整理不动了,再调模型写摘要。- 这里不花钱的整理,就是调用电脑程序帮忙整理
- 花钱的,就是模型帮忙写摘要
图五:真的太长就写摘要

完整压缩不是为了写一篇好看的总结。
它只关心一件事:
压缩完以后,Agent 还能不能继续干活?所以摘要必须保留:
- 当前任务。
- 已经做过什么。
- 看过哪些关键文件。
- 用户要求不能丢什么。
- 下一步应该做什么。
图六:API 已经拒绝了怎么办

这是兜底。
正常情况下,前面的压缩管线应该已经够用。
但如果 API 还是拒绝,就保留最近现场,把更早的内容压成摘要,再重试一次。
compact 工具是手动按钮
第 8 课还给父 Agent 加了一个工具:
compact({ focus })用户明确要求压缩时,模型可以调用它。
例如:
hx agent "先读取 README.md 和 src/agent-loop.js,然后必须调用 compact,focus 保留第 8 课上下文压缩目标,最后用一句话说压缩后还能继续做什么"终端会看到:
> compact focus=保留第 8 课上下文压缩目标
[COMPACT] history reason=manual transcript=.transcripts/transcript-xxx.jsonl这里有一个边界:
- 父 Agent 有
compact。 - 子代理没有
compact。
原因很简单:父 Agent 管主任务的工作桌,子代理只处理局部任务。
怎么跑
沿用第 0 课的 npm link 和 DeepSeek 配置。
验证普通读取
hx agent "读取 references/learn-claude-code/s08_context_compact/README.md,然后用三句话总结上下文压缩的顺序"看这几类输出:
[HOOK] PreToolUse read_file(...)
[HOOK] PostToolUse read_file output_chars=...
[COMPACT] fresh tool_result chars=...能读文件、能总结顺序,就说明旧的工具链没坏。
验证大结果落盘
hx agent "读取 src/agent-loop.js,然后用一句话总结第 8 课新增内容。"如果文件很长,会看到:
[HOOK] PostToolUse read_file output_chars=42255 large-output
[COMPACT] fresh tool_result chars=42255
[COMPACT] persisted fresh tool_result chars=42255再看磁盘:
find .task_outputs/tool-results -maxdepth 1 -type f有文件,就说明长工具结果已经搬出活跃上下文。
验证手动 compact
hx agent "先读取 README.md 和 src/agent-loop.js,然后必须调用 compact,focus 保留第 8 课上下文压缩目标,最后用一句话说压缩后还能继续做什么"看到这行就说明压缩发生了:
[COMPACT] history reason=manual transcript=.transcripts/transcript-xxx.jsonl这一课真正要记住
messages- 模型下一轮要看的工作桌。
.task_outputs/tool-results/- 长工具结果的存放处。
.transcripts/- 完整对话历史的存档处。
compactFreshToolOutput()- 工具结果刚回来时,先判断要不要落盘。
compactBeforeModelCall()- 每轮请求模型前,先收拾上下文。
compactHistory()- 真撑不住时,把长历史压成继续工作用的摘要。
一句话:
上下文压缩就是让模型只背当前有用的东西,不要每轮背着全部旧工具输出。源码
这里只保留主流程。细枝末节先不要看,先把“哪里压缩、什么时候压缩”跑明白。
完整流程图:压缩插在 Agent Loop 的三个位置
先按人话看完整链路:

这张图里只要记住三个插入点:
- 问模型前:先把旧东西收拾一遍。
- 工具回来后:新输出如果太大,马上搬出去。
- API 已经嫌长:做一次应急压缩,再重试。
几个函数先用人话对上
runAgent- 整个 Agent 的主循环。
- 它负责维护
messages,一轮一轮问 DeepSeek,有工具就执行工具,没工具就打印最终回答。
compactBeforeModelCall- 每次问 DeepSeek 前的“收拾桌面”。
- 它不急着找模型,而是先让
messages变轻一点。
toolResultBudget- 专门处理“工具结果太肥”的问题。
- 它把大段输出写进
.task_outputs/tool-results/,上下文里只留保存路径、原始长度和一小段预览。
snipCompact- 专门处理“消息条数太多”的问题。
- 它裁掉中间历史,但会避开孤立的工具消息,避免 DeepSeek 看到断掉的工具调用链。
microCompact- 专门处理“旧工具结果还在占地方”的问题。
- 最近几条工具结果保留全文,更早的长结果换成一句便签。
compactFreshToolOutput- 工具刚跑完时的“入口检查”。
- 如果这次输出已经很长,不等以后再收拾,马上落盘。
compactHistory- 真正的大压缩。
- 它先把完整历史保存到
.transcripts/,再调用 DeepSeek 写连续性摘要,最后把活跃messages替换成system + 摘要。
runCompactTool- 手动压缩按钮。
- 工具本身只说“用户要求压缩了”,真正改写
messages的动作仍由父 Agent Loop 完成。
reactiveCompact- API 已经拒绝后的兜底。
- 走到这里说明前面的预处理还不够,它会保存完整历史、生成摘要、保留最近安全消息,再重试一次。
代码概览
第 8 课只改一条主链路:
hx agent
-> runAgent
-> compactBeforeModelCall 请求模型前先收拾桌面
-> callDeepSeekMessage 把轻一点的 messages 发给模型
-> runToolCall 执行模型要用的工具
-> compactFreshToolOutput 新工具结果太长就立刻落盘
-> role=tool 把短结果或便签回填给下一轮主循环里最关键的是两处。
for (let turn = 1; turn <= AGENT_MAX_TURNS; turn += 1) {
// ① 每次找模型前,先收拾 messages。
await compactBeforeModelCall(messages, stats);
const message = await callDeepSeekMessage(messages, {
tools: TOOL_DEFINITIONS,
tool_choice: "auto",
});
// ② 工具结果回来后,先看太不太长,再决定怎么回填。
for (const toolCall of message.tool_calls || []) {
const output = await runToolCall(toolCall, stats);
messages.push({
role: "tool",
tool_call_id: toolCall.id,
content: compactFreshToolOutput(toolCall.id, output),
});
}
}代码细分
请求模型前先收拾:
async function compactBeforeModelCall(messages, stats) {
toolResultBudget(messages); // 大结果落盘
snipCompact(messages); // 消息太多时裁中间
microCompact(messages); // 旧工具结果占位
if (estimateContextSize(messages) > CONTEXT_COMPACT_THRESHOLD) {
await compactHistory(messages, {
reason: "auto",
focus: "保留当前任务目标、已完成动作、关键文件、用户约束和下一步。",
stats,
});
}
}新工具结果太长,立刻落盘:
function compactFreshToolOutput(toolCallId, output) {
const content = String(output);
if (content.length <= LARGE_TOOL_RESULT_THRESHOLD || isPersistedOutput(content)) {
return output;
}
return persistLargeToolResult({ tool_call_id: toolCallId }, content);
}真的太长,就把完整历史压成摘要:
async function compactHistory(messages, { reason, focus = "", stats } = {}) {
const transcriptPath = writeTranscript(messages);
const summary = await summarizeHistory(messages, { reason, focus });
const systemMessage = messages.find((message) => message.role === "system");
const compactedMessage = {
role: "user",
content: [
`[Conversation compacted by HarnessX. reason=${reason || "manual"}]`,
`Transcript archive: ${transcriptPath}`,
"",
"Continuity summary:",
summary,
].join("\n"),
};
messages.splice(
0,
messages.length,
...(systemMessage ? [systemMessage, compactedMessage] : [compactedMessage]),
);
}最后看工具边界。
父 Agent 有 compact:
const TOOL_HANDLERS = {
// ...
compact: runCompactTool,
};子 Agent 没有:
const SUBAGENT_TOOL_HANDLERS = {
bash: runBashTool,
read_file: runReadFile,
write_file: runWriteFile,
edit_file: runEditFile,
glob: runGlob,
};这一课代码只要抓住这一句:
父 Agent 负责管理主上下文;子代理只做局部任务。