总结

再详细一点的
重点
- 第 9 课要解决的是跨会话记忆:
- 第 8 课的 compact 能让当前会话继续跑。
- 第 9 课的 memory 能让下一次
hx agent还能想起稳定偏好、反复反馈和项目事实。
- 当前做法很朴素:
.harnessx/memory/MEMORY.md是索引。.harnessx/memory/*.md是详情。- 启动 Agent 时先读索引,再按当前任务挑相关详情。
- Agent 结束时,Stop hook 调 DeepSeek 提取新 memory。
- 这一课的第一性原理:
- ① Memory 不是让模型自己变得有记性。
- ② Memory 是 HarnessX 把值得长期保留的信息写到本地文件,下次再塞回 messages。
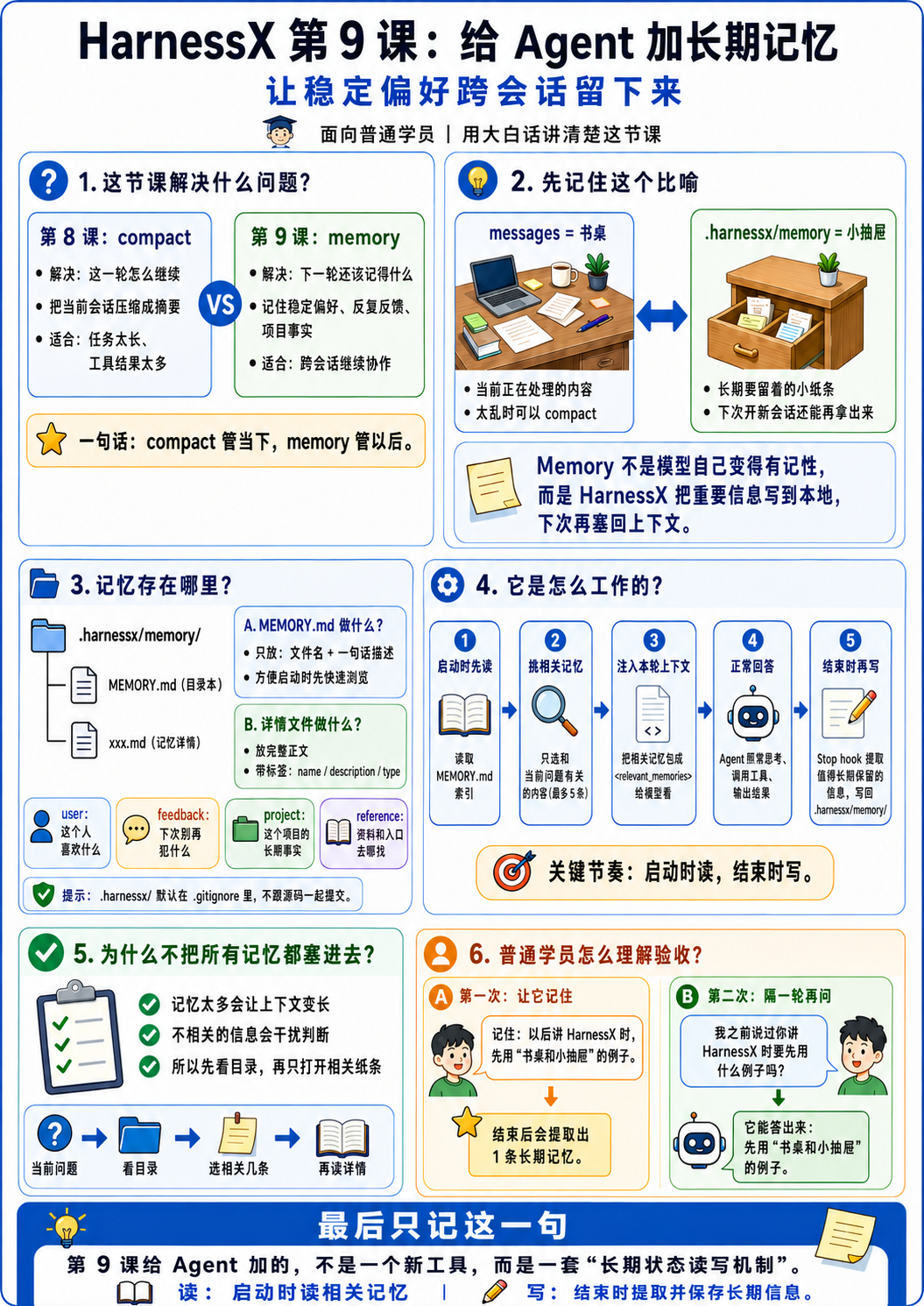
先看完整链路
启动时读,结束时写

两个关键时间点
这张图里最关键的是两个时间点:
- 启动时读:
- 读索引。
- 读相关详情。
- 把 memory 变成模型这轮能看见的上下文。
- 结束时写:
- 从最近对话里提取稳定信息。
- 统一写入
.harnessx/memory/。 - 下次再用。
为什么 compact 之后还需要 memory
用书桌和小抽屉理解两种机制
可以把 messages 想成书桌,把 .harnessx/memory/ 想成小抽屉。
- compact 管桌面:
- 当前任务太长了。
- 工具结果太多了。
- 先把桌面收拾成摘要,让这件事继续做下去。
- memory 管小抽屉:
- 用户说了一个以后还会用的偏好。
- 项目有一个长期约定。
- 下次新开命令时,仍然要能拿出来。
两节课分别解决什么问题
第 8 课解决的是:
这一轮还怎么继续?第 9 课解决的是:
下一轮还应该记得什么?存在哪里
先看本地目录结构
当前实现把长期记忆放在项目本地:
.harnessx/memory/
MEMORY.md
harnessx-desk-drawer-explanation.md先用一张图把目录关系看清楚:

这张图要记住一句话:
MEMORY.md 是目录,不是全文仓库。
真正的记忆正文在旁边的详情文件里。MEMORY.md 只保存索引
MEMORY.md 只做目录本:
- [harnessx-desk-drawer-explanation](harnessx-desk-drawer-explanation.md) - 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码详情文件保存记忆本体
详情文件保存完整内容:
---
name: harnessx-desk-drawer-explanation
description: 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码
type: user
---
用户要求:以后给他讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。frontmatter 是记忆的文件标签
这里的 frontmatter 可以先理解成文件标签:
name:- memory 的稳定名字,也用来生成文件名。
description:- 索引用的一句话,方便下次选择。
type:- 只允许
user、feedback、project、reference。 - 不合法时降级成
project。
- 只允许
四种 type 分别应该保存什么
可以把 type 理解成小抽屉里的四个分格。
同样都是长期记忆,但不要混着放。混着放以后,Agent 下次虽然能翻出来,却不知道这张纸条应该怎么用。
user:用户是谁、喜欢什么
user:- 放“这个用户是谁、喜欢什么、长期偏好是什么”。
- 像抽屉里贴着“这个人”的标签。
- 适合保存表达风格、学习偏好、代码风格、个人习惯。
- 例子:
---
name: harnessx-desk-drawer-explanation
description: 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码
type: user
---
用户要求:以后给他讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。feedback:用户纠正过什么
feedback:- 放“用户纠正过我,以后做事要注意什么”。
- 像抽屉里贴着“下次别再犯”的标签。
- 适合保存协作方式、输出边界、反复被提醒的工作习惯。
- 例子:
---
name: no-mock-for-course-validation
description: 课程验证不要用 mock,要跑真实 hx 命令
type: feedback
---
用户明确反馈:HarnessX 课程能力默认直接调用真实 DeepSeek,不为了本地验证新增 mock 或 fake model。project:项目有哪些长期事实
project:- 放“这个项目现在是什么情况、有哪些长期约定”。
- 像抽屉里贴着“这个项目”的标签。
- 适合保存项目入口、当前课程进度、仓库边界、重要架构决定。
- 例子:
---
name: harnessx-current-mainline
description: HarnessX 当前主线是极简 Node.js src 结构
type: project
---
当前 HarnessX 主线只在 src/ 里实现课程能力,不恢复旧归档分支的 packages/cli 多包结构。reference:以后去哪里找资料
reference:- 放“以后要去哪找资料、线索、入口”。
- 像抽屉里贴着“地图”的标签。
- 适合保存参考教程、本地源码位置、常用文档入口、排查线索。
- 例子:
---
name: learn-claude-code-s09-memory-reference
description: 第 9 课 Memory 的本地参考材料位置
type: reference
---
第 9 课 Memory 主要参考 references/learn-claude-code/s09_memory/README.md 和 code.py。用一句话判断应该放进哪个分格
普通学员可以先用这句判断:
这张纸条是在说人,就放 user。
这张纸条是在说我以后怎么做事,就放 feedback。
这张纸条是在说当前项目事实,就放 project。
这张纸条是在说资料去哪找,就放 reference。
.harnessx/已经加入.gitignore。这表示 memory 是本机运行状态,不跟源码一起提交。
怎么读
runAgent 启动时读取 memory
读 memory 发生在 runAgent() 刚开始。
// 第 9 课新增:用户任务进来后,先读取长期 memory。
const memoryIndex = readMemoryIndex();
const relevantMemories = await loadRelevantMemories(text);
// 找到相关详情时,把它们放到本轮 user message 前面。
const userContent = relevantMemories
? `${relevantMemories}\n\nUser request:\n${text}`
: text;
const messages = [
{ role: "system", content: buildSystemPrompt(memoryIndex) },
{ role: "user", content: userContent },
];这段代码做了两件事:
readMemoryIndex():- 只读
MEMORY.md。 - 让 system prompt 知道当前项目有哪些长期记忆。
- 只读
loadRelevantMemories(text):- 看当前用户任务。
- 从详情文件里挑最多 5 条相关 memory。
- 包成
<relevant_memories>注入本轮对话。
memory 最终怎样进入 user message
模型看到的大概是:
<relevant_memories>
下面是 HarnessX 之前记住的长期信息。回答当前问题时优先遵守这些信息。
<memory name="harnessx-desk-drawer-explanation" type="user" source="harnessx-desk-drawer-explanation.md">
用户要求:以后给他讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。
</memory>
</relevant_memories>
User request:
我之前说过你讲 HarnessX 时要先用什么例子吗?它能回答出来,不是因为模型自己记得。它是这一轮又看见了那张小纸条。
怎么选相关 memory
为什么不能把所有 memory 都发出去
先别看函数名。
想象一下:小抽屉里以后会有很多纸条。
- 有的纸条写用户偏好:
- “讲 HarnessX 时先用书桌和小抽屉的例子。”
- 有的纸条写项目事实:
- “当前主线只在 src/ 里写最小 Node.js 课程代码。”
- 有的纸条写参考资料:
- “第 9 课参考 references/learn-claude-code/s09_memory/README.md。”
现在用户问:
hx agent "我之前说过你讲 HarnessX 时要先用什么例子吗?"这时候不应该把抽屉里所有纸条都倒给模型。
原因很简单:
- 纸条越多,
messages越长。 - 不相关的纸条会干扰模型判断。
- 当前问题只问“讲 HarnessX 用什么例子”,只需要那张用户偏好纸条。
所以 loadRelevantMemories() 做的事情很像整理抽屉:
先看用户这次问什么。
再看抽屉目录里有哪些纸条。
只拿出跟这次问题有关的几张。先看完整选择流程
流程是这样:

DeepSeek 分拣与关键词兜底
这里有两个关键判断:
- 第一选择:
- 让 DeepSeek 当一次“分拣员”。
- 它只看当前问题和 memory 目录,不执行工具,不回答用户。
- 它只返回编号,例如
[0]。
- 第二选择:
- 如果这个分拣请求失败,就用关键词匹配兜底。
- 例如用户问题里有“书桌”“抽屉”“HarnessX”,就去 memory 的 name、description、body 里找这些词。
第一步:把本地 memory 整理成轻量目录
对应代码先把 memory 做成目录:
const catalog = memories
.map((memory, index) => `${index}: ${memory.name} - ${memory.description}`)
.join("\n");这里最容易误解。
本地每条 memory 详情文件本来长这样:
---
name: harnessx-desk-drawer-explanation
description: 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码
type: user
---
用户要求:以后给他讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。但在“选择相关 memory”这一步,HarnessX 不会把所有详情正文都发给 DeepSeek。
它只抽出每条 memory 的两个字段:
namedescription
然后拼成一个很轻的目录。
目录大概长这样:
0: harnessx-desk-drawer-explanation - 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码
1: harnessx-current-mainline - HarnessX 当前主线是极简 Node.js src 结构
2: learn-claude-code-s09-memory-reference - 第 9 课 Memory 的本地参考材料位置这一步可以理解成:
不是把所有纸条全文倒给分拣员。
只是把抽屉目录递给分拣员。
分拣员先看目录,决定要打开哪几张纸条。第二步:看懂目录与记忆本体怎样包装
把这个包装过程画出来就是这样:

这张图要看懂两次发送的区别:
- 发给“分拣员”DeepSeek 的是目录:
namedescription- 当前用户问题
- 发给主 Agent 的才是详情正文:
<relevant_memories>- 被选中的 memory 本体
- 原始
User request
第三步:把目录发给分拣员 DeepSeek
然后发一个很小的模型请求:
const message = await callDeepSeekMessage([
{
role: "user",
content:
"请根据当前用户请求,从 memory catalog 中选择明确相关的 memory。\n" +
"只返回 JSON 数组,例如 [0, 3]。如果没有明确相关项,返回 []。\n" +
`User request:\n${prompt.slice(0, 2000)}\n\n` +
`Memory catalog:\n${catalog}`,
},
]);注意这次调用只传了一个参数:
callDeepSeekMessage(messages)它没有传 tools,也没有传 tool_choice。
所以这不是一次 Agent 工具调用,只是一次普通的 Chat Completions 请求。DeepSeek 不能读文件,不能调用 bash,不能写 memory,它只能根据这段文本返回一个答案。
第四步:看清真正发出的 HTTP 请求体
如果把 callDeepSeekMessage() 里面真正发出去的请求体展开,大概长这样:
{
"model": "deepseek-chat",
"messages": [
{
"role": "user",
"content": "请根据当前用户请求,从 memory catalog 中选择明确相关的 memory。\n只返回 JSON 数组,例如 [0, 3]。如果没有明确相关项,返回 []。\n最多选择 5 条。\n\nUser request:\n我之前说过你讲 HarnessX 时要先用什么例子吗?\n\nMemory catalog:\n0: harnessx-desk-drawer-explanation - 讲 HarnessX 时先用书桌和小抽屉的例子再讲代码\n1: harnessx-current-mainline - HarnessX 当前主线是极简 Node.js src 结构\n2: learn-claude-code-s09-memory-reference - 第 9 课 Memory 的本地参考材料位置"
}
],
"stream": false
}HTTP 层还是第 0 课讲过的那套:
POST https://api.deepseek.com/chat/completions
Content-Type: application/json
Authorization: Bearer <DEEPSEEK_API_KEY>这次最关键的参数只有三个:
model:- 用哪个 DeepSeek 模型,默认是
deepseek-chat。
- 用哪个 DeepSeek 模型,默认是
messages:- 只有一条
user消息。 - 消息里包含当前用户问题和 memory 目录。
- 目录只有
name + description,没有所有 memory 正文。
- 只有一条
stream:- 这里是
false,等 DeepSeek 一次性返回完整结果。
- 这里是
没有 tools 这个字段也很重要。
这意味着本轮 DeepSeek 只是在做选择题:
从 0、1、2 这些 memory 编号里,选出跟用户问题相关的编号。第五步:DeepSeek 只返回相关编号
期望返回值就是:
[0]这个请求不是让 DeepSeek 回答用户。
它只让 DeepSeek 做分拣:
用户问的是“讲 HarnessX 要先用什么例子”。
目录里第 0 条讲的正是这个。
所以返回 [0]。第六步:按编号读取详情并交给主 Agent
拿到 [0] 后,代码再去读第 0 条详情文件,把正文包进 <relevant_memories>。
这时才会读取 memory 本体。
也就是先选中:
[0]再打开:
.harnessx/memory/harnessx-desk-drawer-explanation.md然后把详情正文包装成这样,交给主 Agent 这一轮使用:
<relevant_memories>
下面是 HarnessX 之前记住的长期信息。回答当前问题时优先遵守这些信息。
<memory name="harnessx-desk-drawer-explanation" type="user" source="harnessx-desk-drawer-explanation.md">
用户要求:以后给他讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。
</memory>
</relevant_memories>
User request:
我之前说过你讲 HarnessX 时要先用什么例子吗?所以整条链路是:
选择阶段:发目录,不发全文。
使用阶段:只把选中的详情正文包装后发给主 Agent。side-query 失败时怎样降级
如果这个 side-query 失败,比如网络错误、JSON 解析失败,就降级为关键词匹配:
return selectRelevantMemoriesByKeyword(prompt, memories, maxItems);关键词匹配更笨,但够当兜底。
这一层的原则是:
选得准最好。
选不准也不要让 hx agent 崩。
最坏情况就是这轮不注入 memory,Agent 仍然能正常回答。怎么写
写 memory 发生在 Agent 准备结束的时候。
先看写入流程图:

这张图里有一个关键点:
DeepSeek 只负责判断“哪些信息值得记”。
真正写文件的是 HarnessX 本地代码。agent-loop.js 注册了 Stop hook:
registerHook("Stop", summaryHook);
registerHook("Stop", memoryHook);summaryHook 还是第 4 课留下来的统计日志。
memoryHook 是这一课的新动作:
async function memoryHook(messages) {
try {
const result = await extractMemoriesFromStop(messages);
if (result.written > 0) {
console.log(`[MEMORY] extracted ${result.written} new memories`);
}
} catch (error) {
console.log(`[MEMORY] extraction skipped: ${error.message}`);
}
return null;
}它只做三件事:
- 把最近 messages 交给
extractMemoriesFromStop()。 - 如果真写入了新 memory,就打印数量。
- 如果失败,只打印 skipped,不伪造记忆。
真正提取时,HarnessX 会再请求一次 DeepSeek:
const message = await callDeepSeekMessage([
{
role: "user",
content:
"请从下面这段 HarnessX Agent 对话里提取需要跨会话长期记住的信息。\n" +
"只提取明确、稳定、以后还会用到的信息,例如用户偏好、反复反馈、项目事实、常用入口。\n" +
"返回严格 JSON 数组,不要 Markdown,不要解释。\n" +
"每个元素格式为 {\"name\":\"kebab-case-name\",\"type\":\"user|feedback|project|reference\",\"description\":\"一句话索引\",\"body\":\"完整中文说明\"}。\n" +
"如果没有新增信息,返回 []。\n\n" +
`Existing memories:\n${existing}\n\n` +
`Dialogue:\n${dialogue}`,
},
]);这里要注意:
- DeepSeek 只返回 JSON。
- DeepSeek 不直接写文件。
- 写文件的是本地
writeMemoryCandidate()。
这能避免模型自己乱写 .memory、.claude-memory.md 之类的文件。
怎么跑
沿用第 0 课的 npm link 和 DeepSeek 配置。
这一课的验证最好分成两条命令看:

第一次验证“写进去”。
第二次验证“读出来”。
先让 Agent 记住一条稳定偏好:
# 这条命令会触发第 9 课机制:
# 1. 本轮 Agent 正常回答。
# 2. Stop hook 调 DeepSeek 提取 memory。
# 3. HarnessX 写入 .harnessx/memory/。
hx agent "记住:以后给我讲 HarnessX 时,先用“书桌和小抽屉”的例子,再讲代码。"关键输出是:
[HOOK] UserPromptSubmit cwd=/Users/liguwe/832/832X
[HOOK] Stop: turns=1, tool_calls=0, blocked=0
[MEMORY] extracted 1 new memories
记住了。以后给你讲 HarnessX 时,我会先用"书桌和小抽屉"的例子打好比方,再深入到代码。再问一次:
# 这条命令会验证读 memory:
# runAgent() 启动时读取 MEMORY.md,
# 再把相关详情注入 <relevant_memories>。
hx agent "我之前说过你讲 HarnessX 时要先用什么例子吗?"关键输出是:
[HOOK] UserPromptSubmit cwd=/Users/liguwe/832/832X
[HOOK] Stop: turns=1, tool_calls=0, blocked=0
是的,之前您说过:讲 HarnessX 时,先用"书桌和小抽屉"的例子,再讲代码。验收标准很明确:
.harnessx/memory/MEMORY.md存在。.harnessx/memory/*.md存在。- 第二次提问能说回第一次保存的偏好。
git status --ignored里.harnessx/是 ignored,不进入源码 diff。
这一课真正要记住
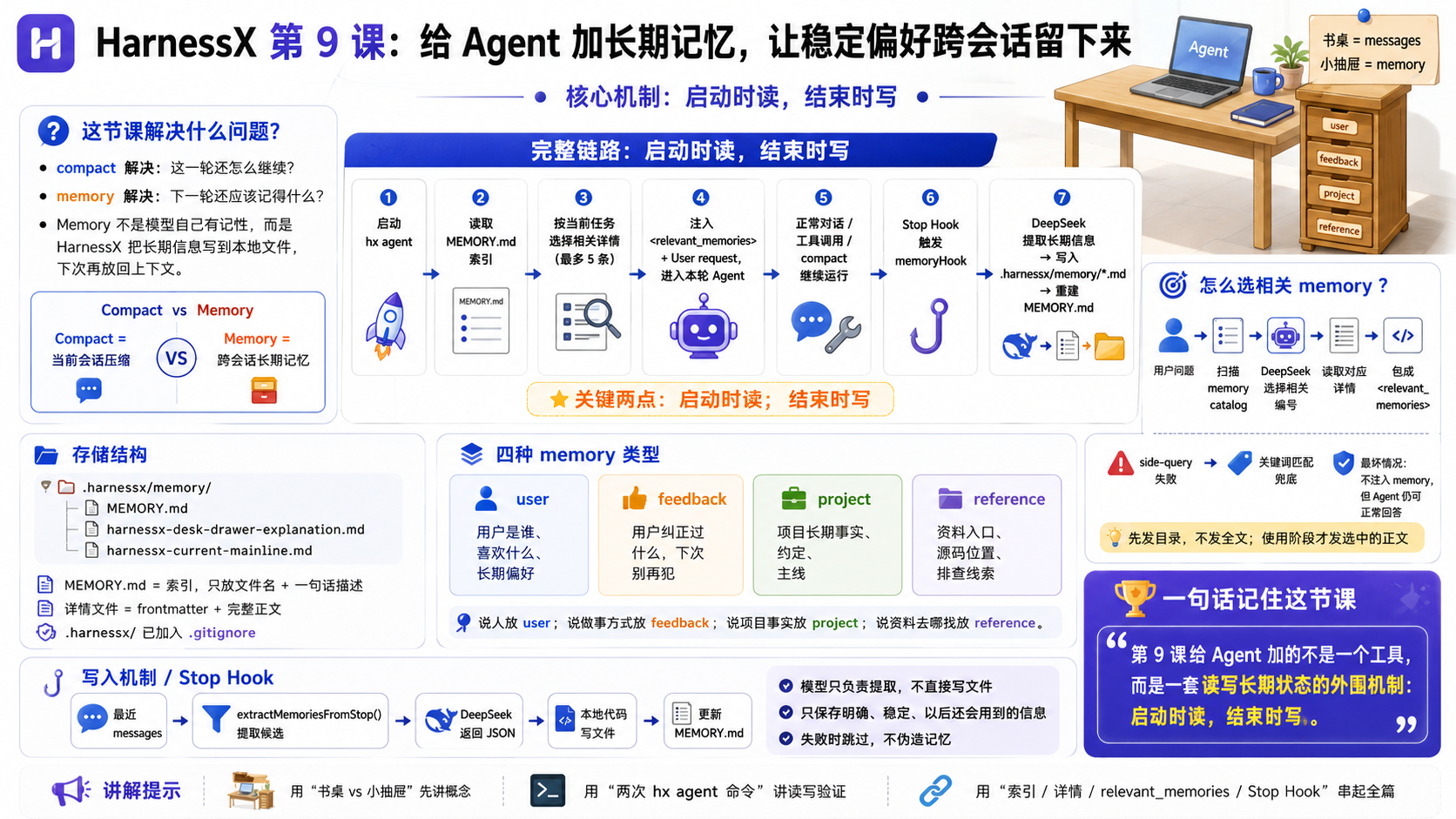
MEMORY.md:- 长期记忆索引,只放文件名和一句话描述。
- memory 详情文件:
- 每条记忆一份 Markdown,frontmatter 放
name、description、type。
- 每条记忆一份 Markdown,frontmatter 放
<relevant_memories>:- 本轮真正注入给模型看的相关记忆正文。
memoryHook:- Stop 阶段自动提取长期信息。
extractMemoriesFromStop():- 调真实 DeepSeek,把最近对话转成结构化 JSON,再交给本地代码写文件。
一句话收束:
第 9 课给 Agent 加的不是一个工具,而是一套读写长期状态的外围机制:启动时读,结束时写。源码
这里保留当前版本主流程。以后代码继续变,这一课要回看的就是 memory 怎样接进 Agent Loop。
代码概览
// src/index.js
// agent 入口没有变,用户仍然只从 hx agent 进来。
if (command === "agent") {
const task = rest.join(" ").trim();
await runAgent(task);
return;
}// src/agent-loop.js
// 第 9 课新增的是 runAgent 开头的 memory 读取。
const memoryIndex = readMemoryIndex();
const relevantMemories = await loadRelevantMemories(text);
const messages = [
{ role: "system", content: buildSystemPrompt(memoryIndex) },
{ role: "user", content: relevantMemories
? `${relevantMemories}\n\nUser request:\n${text}`
: text },
];// src/agent-loop.js
// 第 9 课新增的是 Stop 结束后的 memory 提取。
registerHook("Stop", summaryHook);
registerHook("Stop", memoryHook);
async function memoryHook(messages) {
const result = await extractMemoriesFromStop(messages);
if (result.written > 0) {
console.log(`[MEMORY] extracted ${result.written} new memories`);
}
}// src/memory.js
// memory 文件统一写到 .harnessx/memory/。
const MEMORY_DIR = ".harnessx/memory";
const MEMORY_INDEX = "MEMORY.md";
const MEMORY_TYPES = new Set(["user", "feedback", "project", "reference"]);代码细分
先看 system prompt 怎么知道 memory 索引。
function buildSystemPrompt(memoryIndex = "") {
const memorySection = memoryIndex
? [
"Project memory index:",
memoryIndex,
"这些是 HarnessX 长期记住的信息索引。当前请求相关的 memory 正文会在用户消息里以 <relevant_memories> 注入;如果正文和本轮任务相关,必须优先遵守。",
].join("\n")
: [
"Project memory index: (empty)",
"长期 memory 会在用户明确表达稳定偏好、反复反馈或项目事实后写入。",
].join("\n");
return [...BASE_SYSTEM_PROMPT, memorySection].join("\n");
}这里有一个关键约束:
// 用户说“记住”时,模型只确认。
// 真正写文件由 HarnessX Stop hook 做。
"用户要求你记住偏好、反馈或项目事实时,只要简短确认,不要自行创建 .memory、.harnessx、.claude-memory.md 或其他记忆文件。"再看读取索引。
export function readMemoryIndex() {
const indexPath = memoryIndexPath();
if (!existsSync(indexPath)) {
return "";
}
return readFileSync(indexPath, "utf8").trim();
}没有 memory 时返回空字符串。
这让第 9 课在第一次运行时也能正常跑。
再看加载相关详情。
export async function loadRelevantMemories(prompt, maxItems = MAX_RELEVANT_MEMORIES) {
const memories = await selectRelevantMemories(prompt, maxItems);
if (!memories.length) {
return "";
}
return [
"<relevant_memories>",
"下面是 HarnessX 之前记住的长期信息。回答当前问题时优先遵守这些信息。",
...memories.map((memory) => formatMemoryForPrompt(memory)),
"</relevant_memories>",
].join("\n\n");
}这里输出的不是给人看的文档。
它是下一次 DeepSeek 请求里的 user message 前缀。
再看写入候选。
function writeMemoryCandidate(candidate) {
const name = sanitizeName(candidate.name);
const type = MEMORY_TYPES.has(candidate.type) ? candidate.type : "project";
const description = String(candidate.description || "").trim();
const body = String(candidate.body || "").trim();
// name、description、body 缺一个就不写。
// description 或 body 重复,也不写。
if (!name || !description || !body || isDuplicateMemory(description, body)) {
return false;
}
mkdirSync(memoryDirPath(), { recursive: true });
writeFileSync(
path.join(memoryDirPath(), `${name}.md`),
[
"---",
`name: ${name}`,
`description: ${escapeFrontmatterValue(description)}`,
`type: ${type}`,
"---",
"",
body,
"",
].join("\n"),
"utf8",
);
return true;
}这段代码的边界很清楚:
- 只写结构完整的 memory。
- 只接受四种 type。
- 文件名先 sanitize。
- 基础去重只看 description 和 body。
最后看重建索引。
function rebuildMemoryIndex() {
const dir = memoryDirPath();
mkdirSync(dir, { recursive: true });
const lines = listMemoryFiles().map(
(memory) => `- [${memory.name}](${memory.filename}) - ${memory.description}`,
);
writeFileSync(memoryIndexPath(), lines.length ? `${lines.join("\n")}\n` : "", "utf8");
}每次新详情文件写入后,索引都从当前文件夹重新生成。
这比增量 append 更笨,但更适合课程代码:
- 文件夹里有什么,索引就是什么。
- 不需要维护额外状态。
- 初级程序员顺着代码能看明白。