重点
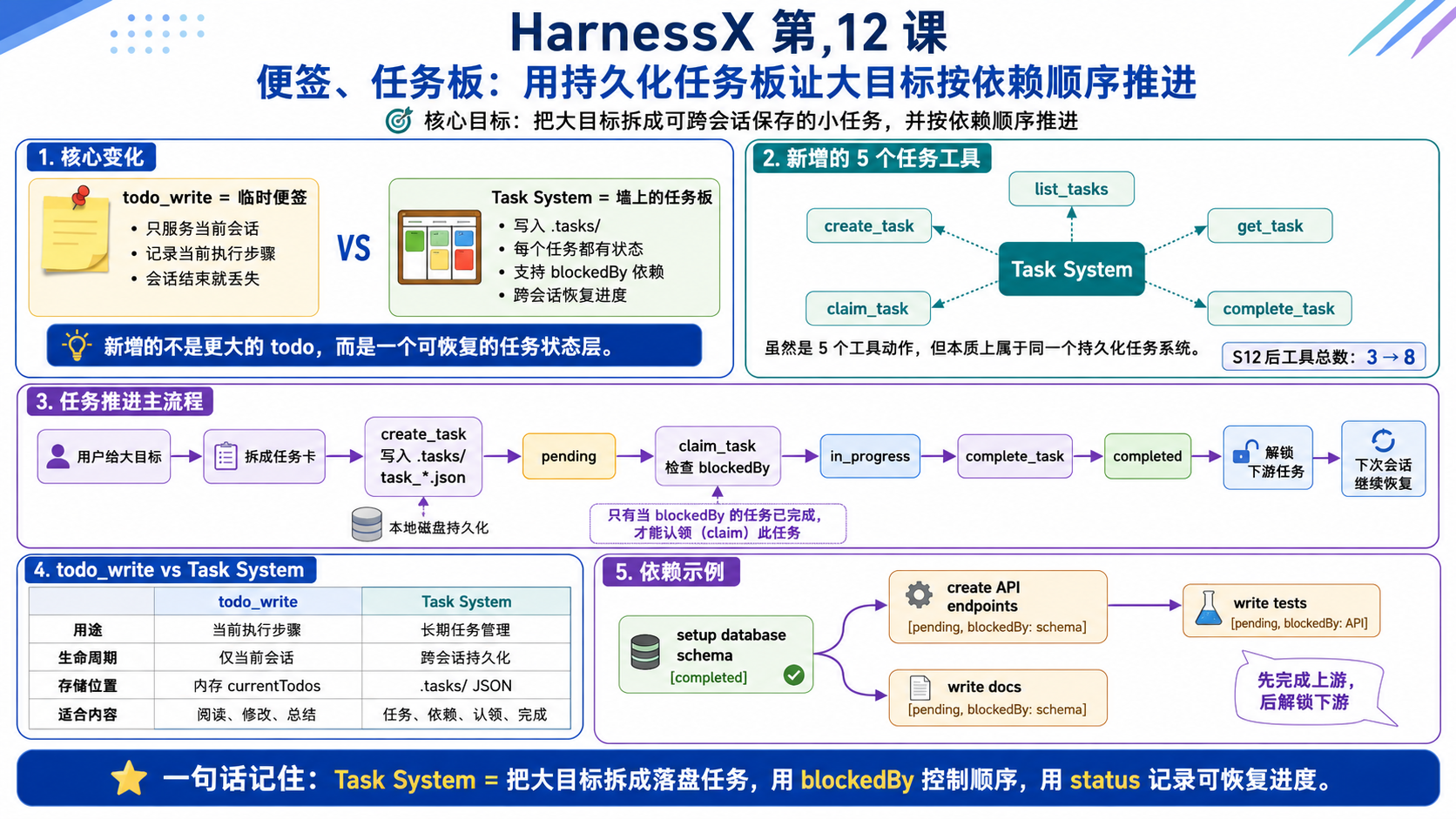
第 12 课当前要做的是:把“大目标” 拆成能跨会话保存的小任务,并且让这些任务按依赖顺序推进。
第 5 课的 todo_write 像一张临时便签。它适合当前这一轮对话里提醒 Agent:先看文件,再改代码,最后总结。
第 12 课的 Task System 像贴在墙上的任务板。它不是临时步骤,而是长期工单:
- 每个任务都落成一个 JSON 文件。
- 每个任务都有状态。
- 每个任务可以声明自己被哪些上游任务挡住。
- Agent 可以先认领能做的任务,做完后解锁后面的任务。
- 关掉当前会话以后,
.tasks/还在,下一次还能接着看。- 这个很关键,即使 ”关掉任务“ ,重新打开会话,还能够恢复
- 因为都在本地
这节课真正新增的不是一个更大的 todo,而是一个可恢复的任务状态层。

用装修工地排工单理解 Task System
把一个软件项目想成装修一间房。
你不能一上来就刷墙。
- 水电没走完,墙面不能封;
- 墙面没封,油漆不能刷;
- 油漆没干,家具不能进场。
如果只有一张临时便签,工人今天可能写:
# 当前会话里的临时步骤
先看户型图
再买水管
然后通知电工这张便签对今天有用,但它不适合管理整个装修项目。明天换一个工人,他不知道哪些工单已经完成、哪些还被上游挡住。
Task System 做的是墙上的工单板:

这个例子里,blockedBy 就是“必须先完成谁”。 换言之 ”某个工单依赖另外一个工单“
封墙被走水电挡住。刷漆被封墙挡住。装灯也被封墙挡住。
Agent 想认领任务时,不能只看自己想做什么。它要先看这个任务的 blockedBy 里所有上游任务是不是都已经 completed。
整体流程
第 12 课没有改掉 Agent Loop。按照参考课的事实,它是在原来的基础工具上新增 5 个任务工具。
原教程表格里写的是:
# S11
bash, read_file, write_file (3)
# S12
+ create_task, list_tasks, get_task, claim_task, complete_task (8)也就是:S12 之后工具总数从 3 个变成 8 个。新增的 5 个工具分别是:
create_tasklist_tasksget_taskclaim_taskcomplete_task
但从架构理解上,它不是五套机制,而是一套 Task System,被拆成五个 function calling 动作。

关键点是职责分开:
- Agent Loop
- 仍然负责请求模型、执行工具、回填结果。
- Task System
- 只负责任务 JSON 的创建、读取、认领、完成。
- System Prompt
- 只负责告诉模型:
- 什么时候用便签,什么时候用任务板。
- 只负责告诉模型:
如果从架构层看,它其实是在原来的 Agent Loop 旁边加了一块“本地状态板”。

这张图比代码重要。它说明第 12 课没有把 Agent 变复杂,只是把“任务进度”从 messages 里拿出来,放到一个稳定地方。
事实是新增 5 个工具,但它们归属同一个任务系统
从 tools 列表看,第 12 课确实新增了 5 个工具。模型能看到的不是一个叫 task_system 的总工具,而是 5 个独立工具名。

但这 5 个工具不是 5 个独立系统,它们共享同一个 .tasks/ 状态目录,共同组成 Task System。
这里的取舍更像 HTTP API 设计。
你可以做一个大接口:
POST /task-system
{ "action": "claim", "task_id": "task_123" }也可以拆成更明确的动作:
POST /tasks
GET /tasks
GET /tasks/task_123
POST /tasks/task_123/claim
POST /tasks/task_123/complete第 12 课选后者,因为教学和模型调用都更清楚:
- 每个动作的参数更少。
- 每个动作的语义更明确。
- 模型不用自己猜
action字段该填什么。 - HarnessX 本地分发也更简单。
- 以后看日志时,
> claim_task比> task_system action=claim更直观。
但从架构上,它仍然是一个能力:持久化任务板。
TodoWrite 和 Task System 的分工
这两个东西最容易混。
todo_write 是 Agent 自己手里的小纸条。它记录“我接下来几步怎么做”。
Task System 是项目墙上的工单板。它记录“这个项目有哪些任务,谁挡住谁,做到哪一步了”。

一个具体例子:
- 用户说“帮我完成一个模块改造”:
- Agent 可以先用
todo_write写当前执行步骤。 - 如果这个目标要拆成
数据库、API、测试、文档这些长期任务,就用create_task写进.tasks/。
- Agent 可以先用
- 用户说“列出任务板,认领能做的任务”:
- 这不是临时便签问题。
- 应该走
list_tasks和claim_task。
任务板上的数据关系
一个任务不是一段代码,而是一张卡片。
这张卡片上最重要的是三块信息:
status:这张卡现在走到哪一步。owner:谁认领了它。blockedBy:它被哪些上游任务挡住。

这张类图 把“任务板、任务卡、磁盘文件” 三件事画清楚。
一个任务怎么从 pending 走到 completed
Task System 的状态很少,故意保持简单。

第 12 课只实现这条最小链路:
create_task:- 创建
pending任务。 - 写入
.tasks/task_*.json。
- 创建
claim_task:- 检查任务必须是
pending。 - 检查
blockedBy里的上游任务都必须是completed。 - 通过后写入
owner: "agent",状态改成in_progress。
- 检查任务必须是
complete_task:- 检查任务必须是
in_progress。 - 状态改成
completed。 - 扫描其他任务,找出刚刚被解锁的下游任务。
- 检查任务必须是
这里故意不做三件事:
- 不做环检测。
- 不做 release / unassign。
- 不做 worktree 隔离。
这些不是本课核心。当前只要讲清楚“任务图可以落盘,依赖会挡住任务开始”。
工具调用的一来一回
模型不会直接改 .tasks/。它只会在返回里提出工具调用。
HarnessX 收到工具调用以后,本地 Node.js 代码才真正写 JSON 文件。

这一来一回要看清楚:
- 程序发给 DeepSeek 的是
messages和工具说明。 - DeepSeek 返回的是
tool_calls。 - HarnessX 本地执行工具。
- 工具结果再作为
role: "tool"回填给模型。 - 下一轮模型才能基于刚创建出来的任务 ID 继续创建
依赖任务。
具体请求和返回长什么样
专业程序员看这一课,最好直接看 function calling 的一来一回。
先看 HarnessX 发给 DeepSeek 的请求。这里省略了无关字段,只保留第 12 课关键部分。
{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "你是 HarnessX 编程 Agent。当前真正启用的工具包括 create_task/list_tasks/get_task/claim_task/complete_task..."
},
{
"role": "user",
"content": "创建一个有依赖的任务板:先创建 setup database schema;再创建 create API endpoints,blockedBy 指向 schema..."
}
],
"tools": [
{
"type": "function",
"function": {
"name": "create_task",
"description": "创建一个跨会话持久化任务。适合记录大目标拆出的任务、任务描述和 blockedBy 依赖。",
"parameters": {
"type": "object",
"properties": {
"subject": { "type": "string" },
"description": { "type": "string" },
"blockedBy": {
"type": "array",
"items": { "type": "string" }
}
},
"required": ["subject"]
}
}
}
],
"tool_choice": "auto"
}模型第一次不会直接替我们写文件。它返回的是“我要调用哪个工具,以及参数是什么”。
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_schema_001",
"type": "function",
"function": {
"name": "create_task",
"arguments": "{\"subject\":\"setup database schema\",\"description\":\"设计并创建数据库表结构\",\"blockedBy\":[]}"
}
}
],
"finish_reason": "tool_calls"
}HarnessX 看到这个 tool_call 后,才在本地执行工具,写入 .tasks/task_*.json。
本地工具执行后的结果会作为 role: "tool" 回填给下一轮模型。
{
"role": "tool",
"tool_call_id": "call_schema_001",
"content": "Created task_1782807117176_3ffd8cca: setup database schema\n{\n \"id\": \"task_1782807117176_3ffd8cca\",\n \"subject\": \"setup database schema\",\n \"status\": \"pending\",\n \"owner\": null,\n \"blockedBy\": []\n}"
}下一轮请求里,messages 已经带上了这个工具结果。模型才能知道 schema 的真实任务 ID,然后创建依赖它的 API 任务。
{
"role": "assistant",
"content": null,
"tool_calls": [
{
"id": "call_api_001",
"type": "function",
"function": {
"name": "create_task",
"arguments": "{\"subject\":\"create API endpoints\",\"description\":\"实现 API 接口\",\"blockedBy\":[\"task_1782807117176_3ffd8cca\"]}"
}
}
],
"finish_reason": "tool_calls"
}所以这里的专业理解是:
- DeepSeek 不直接写
.tasks/。 - DeepSeek 只返回结构化的
tool_calls。 - HarnessX 本地代码才是 side effect 的执行者。
tool_call_id把“模型要求调用工具”和“本地工具执行结果”配对起来。blockedBy必须等第一轮工具结果回来后,才能填入真实任务 ID。
怎么跑
沿用第 0 课的 npm link 和 DeepSeek 配置。
先让 Agent 创建一张有依赖的任务板:
# 这个命令会触发 create_task 多次
# 观察重点:终端里应该出现 > create_task subject=...
# 观察重点:当前目录会生成 .tasks/task_*.json
hx agent "创建一个有依赖的任务板:先创建 setup database schema;再创建 create API endpoints,blockedBy 指向 schema;再创建 write tests,blockedBy 指向 API;再创建 write docs,blockedBy 指向 schema;最后列出任务。"预期能看到类似输出:
# 关键不是 ID 一模一样,而是这些工具调用和状态出现
> create_task subject=setup database schema
Created task_...
> create_task subject=create API endpoints
Created task_... blockedBy=task_...
> list_tasks
[ ] task_...: setup database schema [pending]
[ ] task_...: create API endpoints [pending] blockedBy=task_...再验证依赖会挡住任务开始:
# API 任务依赖 schema;schema 没完成前,API 不能被认领
hx agent "从任务列表里找到 create API endpoints,尝试认领它,并说明为什么现在能不能开始。"预期关键输出:
# 说明 blockedBy 生效了
> claim_task task_id=task_...
Blocked by: task_...最后完成上游任务,观察下游解锁:
# schema 完成以后,API 和 docs 应该被解锁
hx agent "从任务列表里找到 setup database schema,认领并完成它;然后列出刚刚被解锁的任务。"预期关键输出:
> claim_task task_id=task_...
Claimed task_...
> complete_task task_id=task_...
Completed task_...
Unblocked:
- task_...: create API endpoints
- task_...: write docs判断跑通的标准:
.tasks/下出现任务 JSON。- 任务 JSON 里有
status、owner、blockedBy。 - 被依赖挡住的任务不能认领。
- 上游完成后,下游任务出现在
Unblocked里。
这一课真正要记住
Task:一张长期工单。它不是当前步骤,而是可以被保存、认领、完成的项目任务。
blockedBy:任务依赖。意思是“我必须等这些上游任务完成以后才能开始”。
claim_task:认领任务。它不是做完任务,只是把任务从 pending 推到 in_progress。
complete_task:完成任务。它会把任务推到 completed,并检查哪些下游任务被解锁。
todo_write:当前会话的临时便签。它仍然有用,但不要拿它管理跨会话任务图。
# 第 12 课一句话
Task System = 把大目标拆成落盘任务,用 blockedBy 控制开始顺序,用 status 记录可恢复进度。源码
源码
源码部分只保留图和 JS 伪码。代码本身价值不大,真正要记的是这层机制怎么嵌进 Agent Loop,以及状态怎么从模型意图落到磁盘。
源码大流程图

这张图只讲动作,不讲函数名。
第 12 课源码要看懂的不是“某个函数怎么写”,而是这条链路:
用户目标 -> 模型选择任务动作 -> 本地写 .tasks -> 工具结果回填 -> 模型继续决策源码分层图
先看层,不看文件。

第 12 课只新增下面两块:
- 工具分发表里的任务板动作。
- 磁盘状态层里的
.tasks/。
数据流图
再看数据怎么流。

这个数据流有一个关键判断:模型只决定“要调用什么工具”。真正保存任务的是本地工具。
JS 伪码:任务板主流程
这段不是源码,是把第 12 课机制压成一眼能看懂的伪码。
// 用户给大目标
用户输入 = "创建 schema、API、tests、docs 四个任务,并写清依赖"
// Agent Loop 把工具说明发给模型
模型看到 = [
"可以创建任务",
"可以列出任务",
"可以认领任务",
"可以完成任务",
]
// 模型决定先创建第一张任务卡
工具调用 = {
name: "create_task",
input: { subject: "setup database schema" }
}
// 本地工具把任务卡写到墙上
任务卡 = {
id: "task_xxx",
subject: "setup database schema",
status: "pending",
blockedBy: []
}
写入(".tasks/task_xxx.json", 任务卡)
把结果回填给模型("Created task_xxx")JS 伪码:依赖关系怎么形成
// schema 是第一张卡
schema = 创建任务("setup database schema")
// API 必须等 schema
api = 创建任务("create API endpoints", {
blockedBy: [schema.id]
})
// tests 必须等 API
tests = 创建任务("write tests", {
blockedBy: [api.id]
})
// docs 只需要等 schema
docs = 创建任务("write docs", {
blockedBy: [schema.id]
})这比真实函数更重要:blockedBy 不是文字说明,它是任务 ID 组成的依赖边。
JS 伪码:认领任务
function 认领任务(taskId) {
任务 = 从任务板读取(taskId)
if (任务.status !== "pending") {
return "不能认领:它不是等待开始状态"
}
未完成的上游 = 任务.blockedBy.filter((上游ID) => {
上游任务 = 从任务板读取(上游ID)
return 上游任务.status !== "completed"
})
if (未完成的上游.length > 0) {
return "Blocked by: " + 未完成的上游.join(", ")
}
任务.owner = "agent"
任务.status = "in_progress"
保存回任务板(任务)
return "可以开始做了"
}JS 伪码:完成任务并解锁下游
function 完成任务(taskId) {
任务 = 从任务板读取(taskId)
if (任务.status !== "in_progress") {
return "不能完成:它还没有被认领"
}
任务.status = "completed"
保存回任务板(任务)
刚解锁的任务 = 所有任务
.filter(任务 => 任务.status === "pending")
.filter(任务 => 任务.blockedBy 全部都是 completed)
return {
completed: 任务,
unblocked: 刚解锁的任务,
}
}最后收束成一张图

所以第 12 课不是“多了几个函数”。它是把 Agent 的目标推进,从临时对话步骤,升级成了能恢复、能排序、能解锁的任务图。