播客时间: 2026-05-11
播客地址: https://www.xiaoyuzhoufm.com/episode/6a00aa051b7bd50295dfe41d
播客标题: 140. 对姚顺宇的4小时访谈:请允许我小疯一下!在Anthropic和Gemini训模型、技术预测、英雄主义已过去
源于对对姚顺宇的4小时访谈:请允许我小疯一下!在Anthropic和Gemini训模型、技术预测、英雄主义已过去
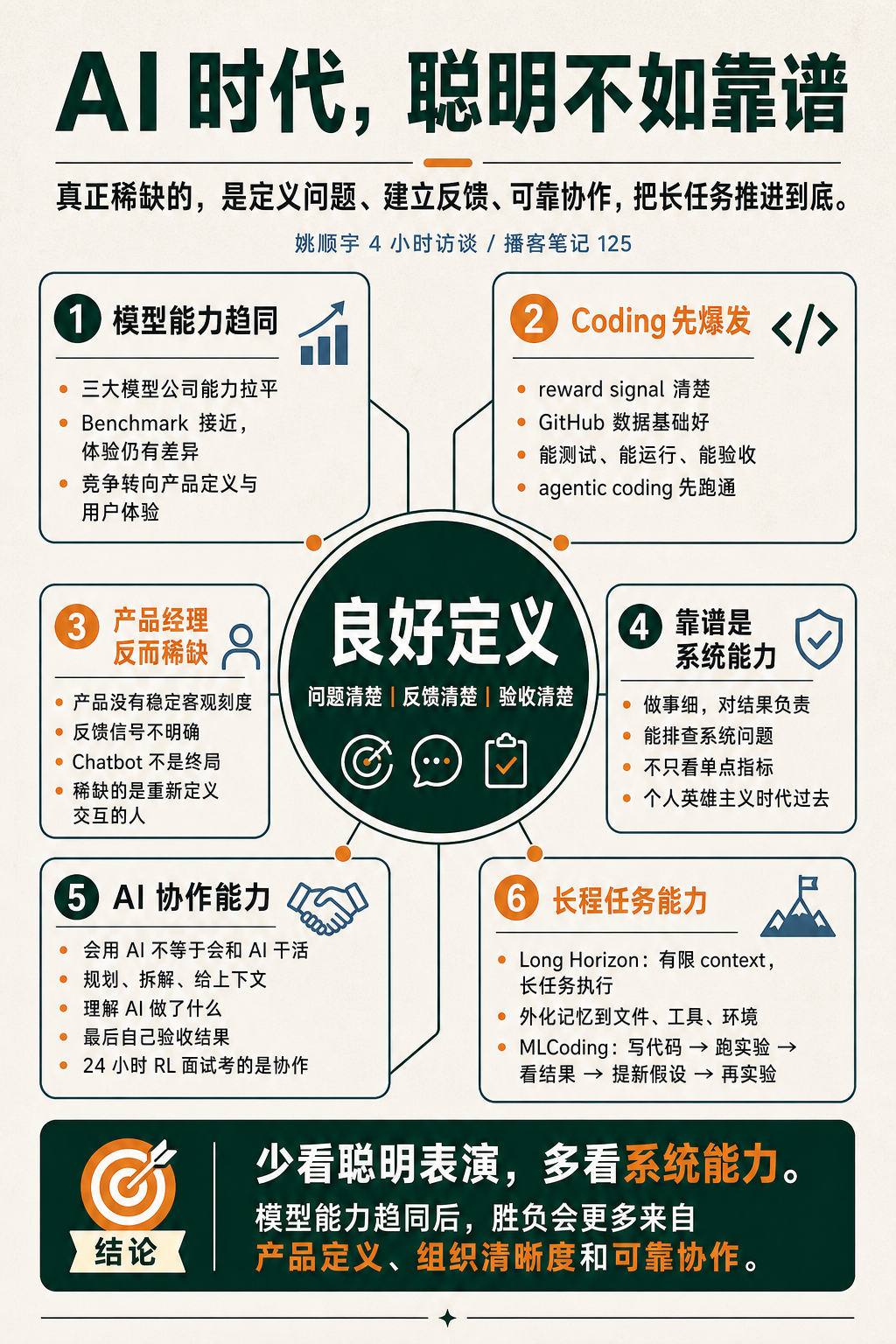
1. 核心观点
- 这期最重要的主线不是“AI 会不会更强”,而是:什么事情是良好定义的。
Coding能先爆发,是因为反馈信号清楚。产品经理反而稀缺,是因为产品没有稳定的客观刻度。靠谱重要,是因为大模型已经进入系统工程阶段,不能只看局部指标。- 讨厌模糊观点,也是因为不良好定义的东西很难判断对错。
- AI 时代不是聪明不重要,而是聪明不够用了。
- 很多想法并不神秘。
- 真正难的是把问题定义清楚,把实验做细,把系统跑稳,把结果负责到底。
- Chatbot 不是终局。
- 它更像搜索的延伸,只是变得更 interactive。
- 模型能力需要
新的产品形态释放。 - 所以真正稀缺的,可能是知道怎么和 AI 协作、怎么重新设计交互的人。
- 不要把“会用 AI”误认为“会和 AI 干活”。
- 让 AI 生成代码不难。
- 难的是知道它做了什么、为什么这么做、哪里可能错、最后怎么验收。
2. 总结
- 核心结论
- 当下 AI 发展由
“浪”推动,而不是由单个个人推动。- 从业者需要靠谱、细致。
- 需要用集体协作应对系统复杂性。
- 模型能力趋同之后,竞争焦点会转向
产品定义与用户体验。Coding是已经验证的成功场景。- 它不是全部 AI 原生应用,但它先跑通了。
- 不同公司文化都可能成功。
- Anthropic 的特点是强执行。
- Google 的特点是工程化。
- 关键不只是组织形式,而是技术领导者的公信力与组织清晰度。
- 当下 AI 发展由
- 行业现状与趋势
- 模型能力现状
- 三大模型公司能力已经拉平。
- Benchmark 分数接近,差异主要来自
噪声。 - 用户实际体验仍能感受到区别。
- Claude 在通用工具和 Agent 表现更好。
- Gemini 在纯推理和日常使用环境较好。
- 技术发展驱动力
- 预训练
scaling law尚未到头。 - 未来几个月仍会继续有进展。
- 当前主要驱动力是算力和数据。
- 算法作用在范式清晰后趋于平滑。
- 多模态生成仍是未解决的科学问题。
- 预训练
- 产品与市场格局
Coding是当前唯一成功的 AI 原生场景。- 它的优势是反馈信号清晰、数据基础好。
Coding产品形态相对单一,优秀程序员标准共识高。- 两种公司能存活
- 足够快,比如那会的Cursor
- 但这类“壳”公司会面临模型公司竞争,比如 claude-code
- 之前cursor 和 Anthropic 也算是良好的合作者
- 市场足够小,例如 Midjourney,也是一种生存策略。
- 足够快,比如那会的Cursor
- 模型能力现状
- 公司文化与组织
- AI 行业特质
- 个人英雄主义时代已经过去。
- AI 是集体协作的系统工程。
- 最重要的从业者特质是“靠谱”。
- 做事细致、对自己负责是关键。
- 很多工作本科生也能胜任。
- 对程序员的建议
- AI 是中心化技术,会让少数人更强。
- 未来程序员需要有效与 AI 协作。
- 重要能力是规划、拆解复杂任务。
- 要理解工作如何适配大组织。
- 具体实现类工作会越来越少。
- 个人经历与选择
- 从物理转 AI,是因为 AI 更容易做实验验证。
- 选择挑战自己不会的事情。
- 在 Anthropic 学习纵向深度。
- 在 Google 学习横向广度。
- 未来可能继续挑战新方向。
- AI 行业特质
3. 为什么产品经理反而稀缺
这期最容易漏掉的点,是他对产品经理的判断。
Coding 好训练,不是因为代码高贵,而是因为它有清楚的反馈信号。
- 一个功能有没有实现,可以测试。
- 输入输出是否匹配,可以判断。
- 代码是否破坏旧逻辑,可以跑回归。
- GitHub 又提供了大量真实数据。
但产品经理的问题反过来。
好的产品没有稳定的客观标准,也没有清楚刻度。
也就是说,产品的反馈信号不明确。
- 什么叫好产品?
- 很多时候只有做出来、让人用了,才知道。
- 什么叫好交互?
- 不是看起来合理就一定成立。
- 什么叫用户体验好?
- 不是一个 benchmark 可以直接打分。
所以产品经理的稀缺,不是“会写需求文档”的稀缺,而是:
- 能不能找到值得做的问题。
- 能不能把模糊需求变成可验证的产品形态。
- 能不能用
新的交互方式释放模型能力。- 比如抖音找到了新的交互模式
- 能不能判断一个产品是不是只有表面热闹。
逐字稿里还提到一个很关键的判断:人类现在主要通过 Chatbot 和 AI 沟通,这个形态本身很粗糙。
Chatbot 更像搜索的延伸。
- 它能回答。
- 它能追问。
- 它能总结。
- 但它还没有真正把模型能力用产品形态释放出来。
所以这里真正稀缺的产品经理,可能不是上一代“摆 feature”的产品经理,而是知道怎么和 AI 协作、怎么改变交互方式的人。
4. Coding 为什么先爆发
Coding 先爆发,是因为它良好定义。
第一,reward signal 清楚。
- 代码能不能跑。
- 测试能不能过。
- 输入输出能不能对。
- 功能有没有实现。
第二,数据基础好。
- GitHub 留下了几十年的代码。
- 代码天然结构化。
- 能从代码构建环境和任务。
第三,需求相对单一。
- 好代码通常有共识:
- 简洁。
- 干净。
- 结构清楚。
- 可维护。
- 抽象合理。
这就是为什么 agentic coding 先跑出来。
它不是因为程序员最难替代,而是因为程序员工作里有一大块刚好最容易被定义、训练和验收。
真正被抬高的,不是敲代码本身,而是:
- 设计代码逻辑。
- 组织上下文。
- 拆解任务。
- 验收结果。
- 判断模型哪里看起来对、其实不对。
5. 靠谱不是性格,是系统能力
“靠谱”这句话很容易被理解成性格评价。
但在这期里,它更像一种系统能力。
靠谱不是:
- 看起来努力。
- 说话稳重。
- 单点指标好看。
- 自己那块做得漂亮。
靠谱是:
- 知道一个实验的限制因素是什么。
- 知道结果好是因为算法、数据,还是更多
flop。 - 知道训练稳定性在大尺度上能不能保持。
- 知道局部收益会不会破坏整体。
- 能对公司、系统和最终结果负责。
这也是为什么个人英雄主义会变危险。
在大模型系统里,一个人拿出漂亮数字不够。
如果只为个人英雄主义做事,就可能破坏整体性。
大模型后面的竞争,不只是天才想法,而是系统排查、工程管理、数据组织、评估和责任。
6. 二十四小时小时强化学习面试题
24 小时强化学习面试题也在讲同一件事。
这个题表面上是让候选人从 0 到 1 做一个强化学习项目,但核心不是考代码。
- 有 AI 之后,写代码本身没那么难。
- 难的是候选人有没有有效利用 AI。
- 更难的是有没有理解 AI 帮他做了什么。
- 如果全盘扔给 AI,一个小时讨论时会露馅。
所以这道题真正考的是:你有没有和 AI 形成协作,而不是把活全权扔给它。
7. Long Horizon 和 MLCoding
Long Horizon 和 MLCoding 是这期后半段最重要的技术方向。
7.1. Long Horizon
Long Horizon 的关键不是无限拉长上下文。
Long Horizon(长程任务能力)
更准确地说,是:
Train with finite context, use as infinite context.
也就是用有限 context 训练,但使用时能做长任务。
这和人很像。
- 人不会记住所有东西。
- 人会忘掉不重要的信息。
- 人会把重要信息外化到文件、工具、环境里。
- 需要时再取回来。
所以长任务的关键不是“什么都塞进上下文”,而是:
- 什么可以忘。
- 什么必须留下。
- 什么要写进外部工具。
- 什么时候检索回来。
- 怎么在多轮、多工具、多环境里不丢目标。
7.2. MLCoding
MLCoding 则是把 AI research 这条链跑完。
不是 AI 帮研究员写几段代码,而是让它逐步完成:
- 写代码。
- 跑实验。
- 看结果。
- 分析哪里不对。
- 提出新假设。
- 设计新代码。
- 跑新实验。
这条链还没完整,但如果跑通,变化会比“AI 会写代码”大得多。 它会变成 AI 加速 AI research 本身。
8. 启示
- 人的注意力很稀缺。
- 4 小时播客如果不压成结构,很快就只剩“听过了”。
- 以后看 AI,先问是不是良好定义。
- 问题是否清楚。
- 反馈信号是否清楚。
- 验收是否清楚。
- 不要低估产品经理。
- 越是模型能力趋同,越需要有人定义产品形态和交互方式。
- 不要把 AI 当外包。
- 全权扔给 AI,最后自己不理解,就是不靠谱。
- 少看聪明表演,多看系统能力。
- 能不能排查。
- 能不能负责。
- 能不能在长任务里不丢目标。