原文: https://x.com/FakeMaidenMaker/status/2055146731625447516
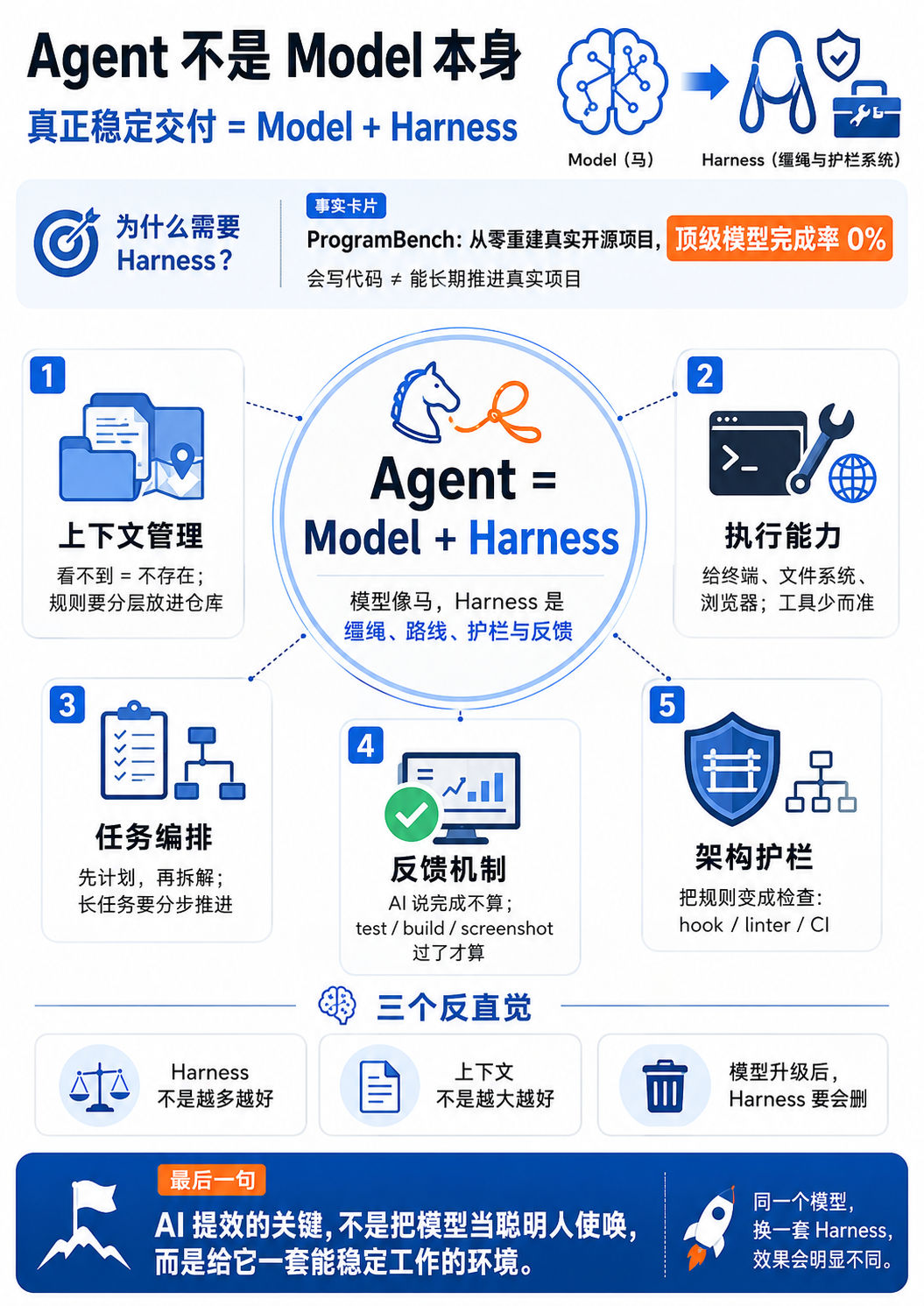
1. 一图甚千言
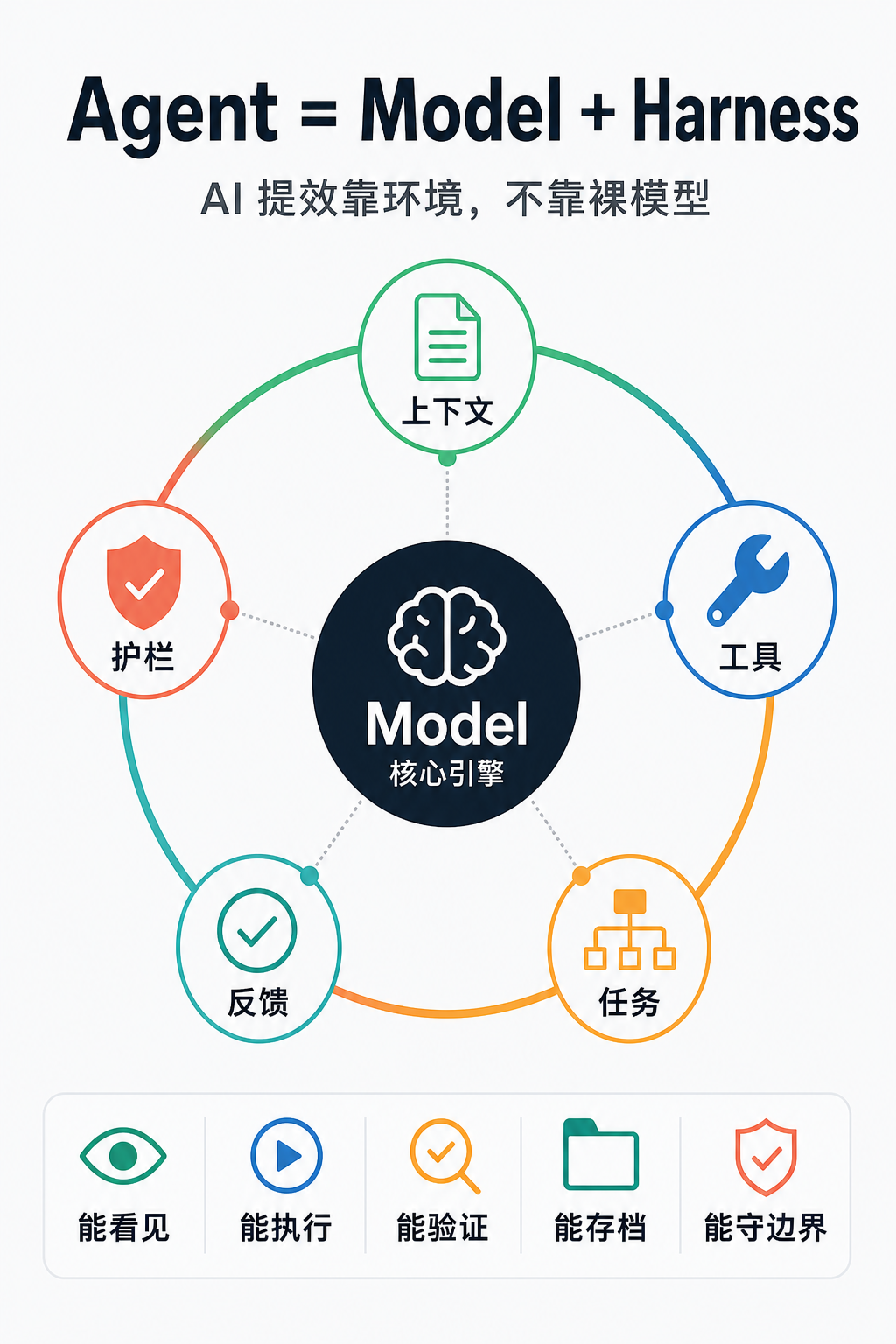

更详细的

2. 一篇论文

- 要求 AI 从零开始完整重建真实的开源软件项目,不允许联网,不看代码相似度,只验证最终行为。
- 结果是:
- Claude Opus 4.7、GPT-5.4、Gemini 3.1 Pro,所有一线模型完成率全部 0%。
- 结论:
- 这不是说 AI 写不出代码。它能写很多代码,能把函数写得很漂亮。
- 但让它从零搭一个能真正跑起来的真实项目,它就会把所有逻辑塞进一个单体文件,没有模块化、没有架构、没有长期规划,最终通不过行为验证。
- 所以,需要
Harness
arXiv 论文原文:《ProgramBench: Can Language Models Rebuild Programs From Scratch?》
3. 划重点

Harness不是一个新工具,而是 AI 周围那套让它能长期干活的工程系统。- 规则怎么给。
- 上下文怎么找。
- 工具怎么接。
- 任务怎么拆。
- 结果怎么验证。
- 架构怎么守住。
- 同一个模型,换一套 Harness,效果好很多。
- LangChain 的例子是:
- 模型权重不变,只优化工程结构,coding agent 在 Terminal-Bench 2.0 上从 52.8 到 66.5。
- OpenAI 的例子是:
- 3 个人用 Codex 5 个月合并约 1500 个 PR,写出约 100 万行代码。
- LangChain 的例子是:
- 这里真正要记住的不是数字,而是判断:
- ==Agent 不是 Model 本身。Agent = Model + Harness。==
裸模型像一个很会写局部代码的人。- 让它自己长期推进真实项目,会开始失控。
- 它缺的不是“更会写代码”,而是可见上下文、可用工具、验证回路和架构边界。
4. Harness 是什么

- 原文把 Harness 翻成马具,这个比喻还行:
- 模型是
马。 - Harness 是
缰绳、鞍、路线、护栏和反馈。
- 模型是
- 放到我自己的工作里,Harness 就是这些东西的总称:
AGENTS.md/CLAUDE.md- skills
- MCP
- hooks
- sub-agents
- browser / terminal / file system
- progress.md / git commit
- tests / lint / screenshots
- permissions / sandbox / rollback
- 重点不是把这些都装上。
- 重点是知道每一块在补 AI 的哪个短板。
- 答不上来,就别加。
5. 五件事

Harness 可以压成五件事:
上下文管理- AI 运行时看不到的东西,就等于不存在。
- 规则不能只在脑子里、聊天里、历史对话里。
- 要写进仓库,分层放。
执行能力----> 给它工具- 模型本身只会输出文本。
- 要给它终端、文件系统、浏览器、MCP、skills。
- 但工具要少而准,不是越多越好。
任务编排- 长任务不能 one-shot。
- 要先计划,再分步做,做完一步验一步。
- 跨窗口任务要靠
progress.md和 git commit 存档。
反馈机制- AI 说“修好了”不算。
- lint、typecheck、test、Playwright、截图、接口请求跑通才算。
- 生成者和评审者最好分开。
架构护栏- AI 会模仿仓库现有模式。
- 好模式会放大,坏模式也会放大。
- 所以架构规则不能只写在文档里,要尽量变成可执行检查。
6. 上下文
- 最重要的一句话:
- 运行时拿不到的知识,对 Agent 来说就是不存在。
- 所以上下文要分层,而不是全塞进模型。
- 可以分三层:
- 第一层:根目录
AGENTS.md/CLAUDE.md。- 只放地图、边界、禁区、必要命令。
- 不要写成几千行百科。
- 第二层:
docs/里的专题文档。- 前端规范、安全规则、API 设计、发布流程都可以拆出去。
- 根规则只负责指路。
- 第三层:原始记录。
- git log、历史 issue、日志、旧对话。
- 不默认加载,只允许搜索。
- 第一层:根目录
- 这跟现在
~/832的方向是一致的:- 根
AGENTS.md管 workspace 边界。 - 子工程自己管自己的 README / AGENTS。
whoami管自我协议。os管长期内容源。- skills 管用户级复用能力。
- 根
- 不能把所有东西都塞到一个“总规则”里。
- 规则越长,模型越容易看不见重点。
7. 工具:多不如精
- 工具是 AI 的手脚。
- 终端让它跑命令。
- 文件系统让它读写代码。
- 浏览器让它看真实页面。
- MCP 让它接外部系统。
- Skills 让它复用稳定工作流。
- 但工具过多会让 Agent 变笨。
- 每一步都多一个选择,就多一个走错路的机会。
- 工具描述、权限、参数也会占上下文。
- Vercel 的 text-to-SQL 案例很值得记住:
- 一开始堆了 schema lookup、query validation、error recovery 等专用工具,成功率 80%。
- 后来删掉 80% 的工具,
- 只让 Claude 用
grep、cat、find、ls读文件,成功率到 100%,速度更快,token 更省。
- 只让 Claude 用
- 对我自己的判断:
- 能用基础工具解决的,不急着封装成复杂工具。
- 只有当某个流程反复做、步骤稳定、失败成本高时,才适合沉淀成 skill。
差生文具多
8. 长任务

- 长任务的失败通常不是模型不会写,而是它想一次写完。
- 上下文用完。
- 前面方案错了,后面又回头改。
- 文件越改越乱。
- 解决办法很普通:
- 先计划。
- 再拆任务。
- 每次只做一块。
- 做完验证。
- 写进
progress.md。 - 提交 git。
- Anthropic 的 Ralph Loop 本质就是这个:
- Initializer Agent 先搭环境、拆功能、写第一份进度、做第一次提交。
- Coding Agent 每一轮先读 git log 和 progress,再挑下一项做,做完提交并更新 progress。
- 这个思路适合长线工程,不一定适合每个小改动。
- 小任务直接做。
- 大任务一定要有外置状态。
9. 反馈
- AI 最容易骗我的地方是:“看起来写完了”。
- 变量名对。
- 缩进对。
- 解释也合理。
- 但一跑就错。
- 所以 Harness 里最确定的一项投资是反馈回路。
- 后端:测试、接口请求、日志。
- 前端:浏览器真实打开、点击、截图。
- 工程:lint、typecheck、build。
- 代码质量:另一个 agent review。
- 生成和评审最好分开。
- 自己写的代码自己 review,天然容易替自己找理由。
- Generator 和 evaluator 分成两个角色,效果会更接近真实 code review。
- 最终标准很简单:
- AI 说完成没有用,证据完成才算完成。
这也是为什么,每次他都要
npm run build,搞得我很烦
10. 护栏
- AI 会放大代码库里的现有模式。
- 仓库干净,它会模仿干净。
- 仓库混乱,它会继续混乱。
- 所以只靠“告诉它要注意架构”不够。
- 要把规则变成检查。
- 可以分三层:
- pre-commit hooks:
- 提交前拦基础问题。
- 架构 linter:
- 拦模块依赖、目录边界、文件大小、禁用调用。
- CI gate:
- 本地绕过了,主干再拦一次。
- pre-commit hooks:
- OpenAI 的做法更进一步:
- 后台定期让 Codex 扫技术债,自动开小 PR 修。
- 这件事背后的判断是:
- AI 写代码越快,技术债产生也越快。
- 清债也要更自动化。
11. 三个反直觉

- Harness 不是越多越好。
- 每个工具、hook、skill、MCP 都要能说清楚它补的能力缺口。
- 说不清楚,就是负担。
- 上下文不是越大越好。
- 长上下文会衰减。
- 关键信息放在中间,模型可能看不见。
- 组织方式比容量更重要。
- Harness 要随着模型进步而删减。
- 每个 Harness 组件都是对模型能力不足的补丁。
- 模型升级后,有些补丁会变成包袱。
- 该删就删。
12. 启示
- 一个 Agent 工具,不只看模型强不强。
- 要看它的 Harness 做得怎么样。
- 好用的 Agent 大概率不是“提示词写得更神”,而是这些基础设施更完整:
- 能读到正确上下文。
- 能使用正确工具。
- 能拆长任务。
- 能自己验证。
- 有权限和架构护栏。
- 对
~/832来说,最该持续维护的是:- 根级
AGENTS.md:workspace 边界。 - 子工程 README / AGENTS:各自规则。
- skills:高频稳定工作流。
auto/:本机自动化执行层。whoami:自我协议和长期判断入口。
- 根级
- 不要把
Harness做成新的垃圾堆。- 能用文件说明的,不写复杂工具。
- 能用命令解决的,不接重 MCP。
- 能靠验证闭环解决的,不靠反复提醒模型。
- 最后:
- AI 提效的关键,不是把模型当聪明人使唤,而是给它一套能稳定工作的环境。