2026-06-12 更新:这篇文章里的判断已经过时。后续真实使用很少,
keones-bug入口也已经删掉。最新复盘见 复盘:老系统自动化的真实 ROI ,一定要问是真需求吗?。
1. 重点
- 通过
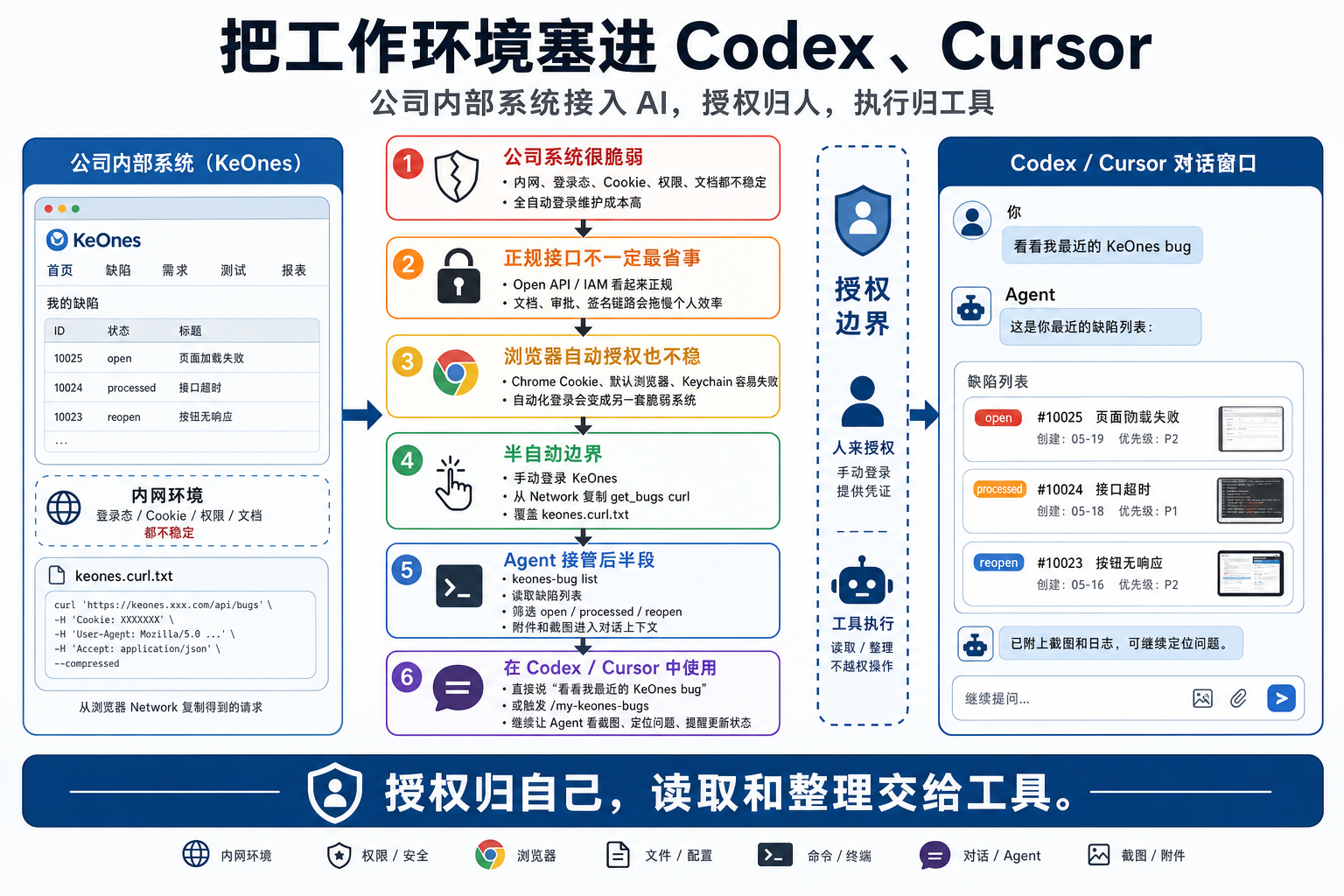
自己复制curl的方式虽然临时,但对于个人来说足够使用,ROI足够高 - KeOnes 的难点
- 在公司内网、登录态、Cookie、文档、权限和浏览器安全链都不稳定。
- 现在没多少人维护这个了
- 所以工具真正应该接管的是复制 curl 之后的部分:
- 解析、请求、筛选、展示、附件落地。
- 所以,没必要为了自动化而自动化
2. 过程记录
- 最开始,想走正规路线:
- Open API、IAM 签名、APPKEY、Token。
- 推进起来特别别扭,比如
- 因为很多东西都不维护,你根本不知道是某个服务是不是已经不维护了,还需要走单独的权限审批等
- 后来,换成浏览器会话模式:
- 既然页面能查,那就复用页面同源接口
- 所以可以自动读 Chrome Cookie、默认浏览器 Cookie、Keychain、浏览器登录态,这些东西本身也很脆。
- 越想把授权自动化,越像是在重新实现一套不稳定的登录系统。
- 最后方案
- 退回到
/Users/liguwe/832/auto/config/keones.curl.txt。 - 这反而是最清楚的:
- 手动登录 KeOnes,从 Network 复制一条完整 curl,工具每次从这个文件解析 URL、headers、Cookie 和 payload。
- 过期了就重新复制,没过期就直接查。
- 退回到
3. 为什么半自动
- 登录是授权,不是普通参数。
- 授权动作应该由人触发,而不是让 Agent 猜浏览器、读 Keychain、追 Cookie 存储格式。那条路看起来更“智能”,
- 但一旦失败,问题会变得很难解释:到底是没登录、Cookie 过期、浏览器不对、Keychain 拦截,还是内网请求被 sandbox 拦住?
keones.curl.txt 把问题压成一个很小的边界:
- 文件存在且登录态有效,工具就读取 bug。
- 文件过期,工具就提示重新复制 curl。
- 网络被 sandbox 拦住,就用只读网络权限重试。
- 页面筛选变化,就重新复制当前页面的 curl。
这个边界没有那么漂亮,但很稳。它不需要长期维护浏览器自动化,也不需要把公司登录系统塞进个人工具里。
4. 真正自动化的部分
KeOnes 这类系统接入 AI,最有价值的不是省掉那一次登录,而是省掉后面所有重复动作。
比如:
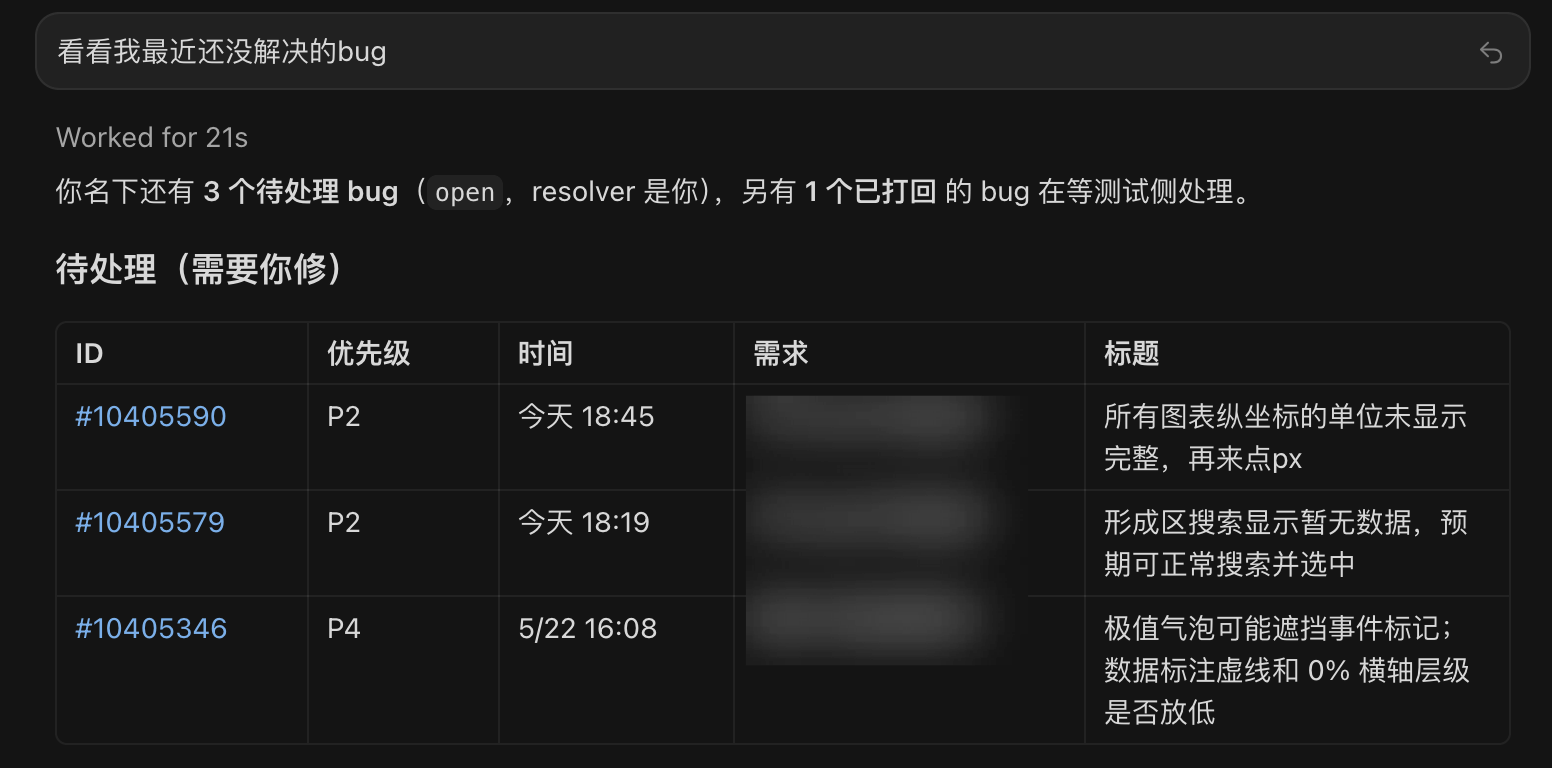
- 不再打开页面扫一遍 bug 列表。
- 不再手动区分
open、processed、reopen。 - 不再点开每条缺陷看截图。
- 不再复制标题、附件、复现步骤给 Agent。
- 不再在页面和代码之间反复搬上下文。
这些才是工具应该做的事。
所以当前 keones-bug 的价值不是“我拥有了一个完美 API 客户端”,而是 “我把 KeOnes 页面上的重复阅读工作搬到了Coding Agent 上下文里”。
这是我和Agent都需要的上下文
5. 如何使用
- 先在 KeOnes 页面里筛选到自己要看的缺陷列表,然后从 Network 里复制
get_bugs的完整 curl,覆盖到/Users/liguwe/832/auto/config/keones.curl.txt。 - 在 Codex 或 Cursor 里直接说 “看看我最近的 KeOnes bug” 或 触发
/my-keones-bugs,Agent 会执行keones-bug list,把缺陷列表、状态和截图附件搬进当前对话。 - 如果要处理某一条 bug,就继续在同一个对话里说
- “看 10405590 的截图”“ 这个问题帮我定位下”
- “修完后提醒我更新状态”,让 Agent 带着当前代码上下文继续往下走。
- 如果登录态过期,就重新打开 KeOnes 页面复制一次 curl;授权e归自己,读取和整理交给工具。
6. 启示
- AI 不是必须把人从链路里完全拿掉,而是应该把人留在最需要判断和授权的位置。
- 对内部系统做自动化,先追求可恢复、可解释、可替换,再追求全自动。
- 如果公司基建本身复杂,很脆弱,就不要把复杂度继续包一层;
- 半自动的意义不是少做一点,而是承认现实:授权归人,执行归工具。
其实同步到语雀上传附件也是这个逻辑,过期了,就手动再粘贴一个
curl.txt就好了