省份数量
#leetcode #2024/09/12 #算法 #DFS
目录
1. 题目及理解
https://leetcode.cn/problems/number-of-provinces/description
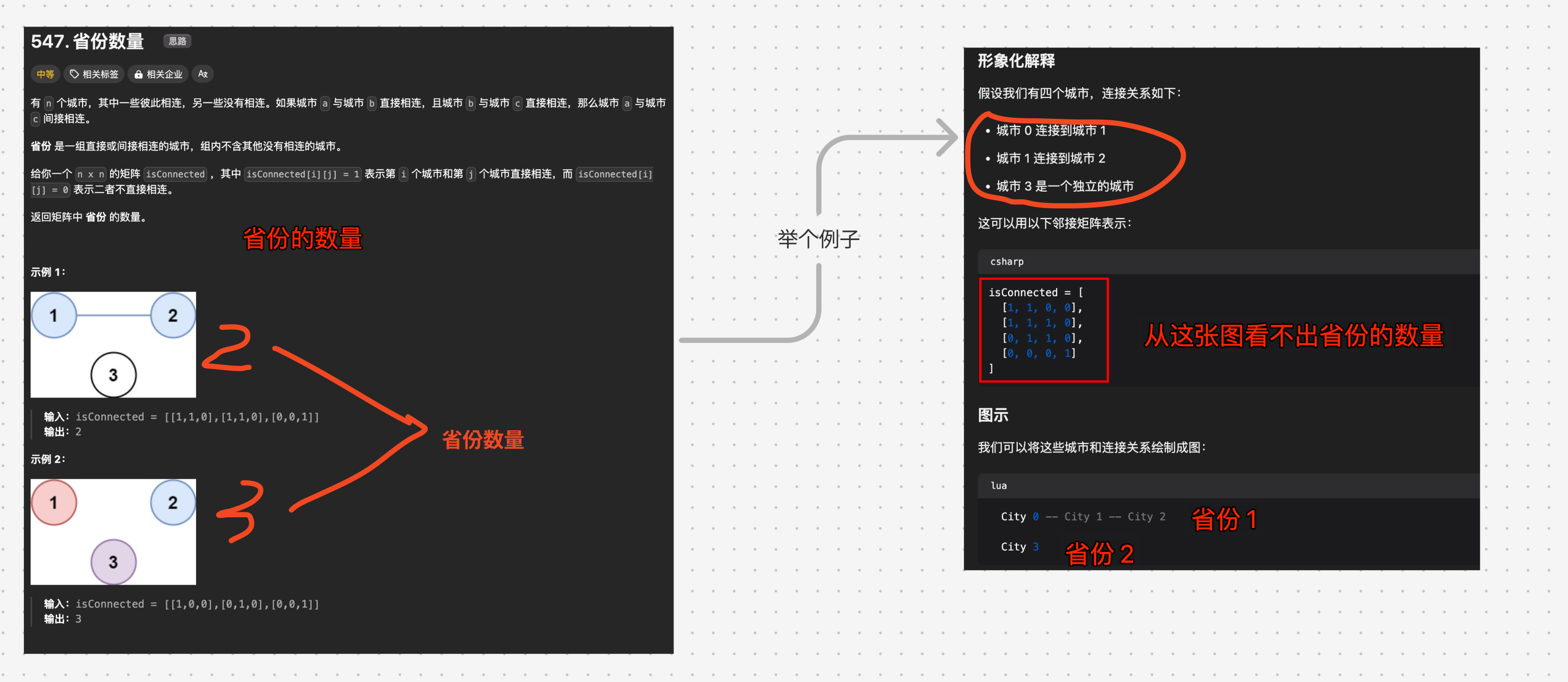
2. 思路一:DFS
- 初始化:创建一个布尔数组
visited,用于记录每个城市是否已被访问 - 遍历城市:
- 对于每个城市,如果它未被访问,则执行 DFS,从该城市出发访问所有与之相连的城市
- DFS 实现
- 递归地访问所有直接相连且未被访问的城市,并标记为已访问。
- 计数省份
- 每次执行新的 DFS 时,意味着发现了一个新的省份,增加省份计数。
2.1. 代码实现及分析
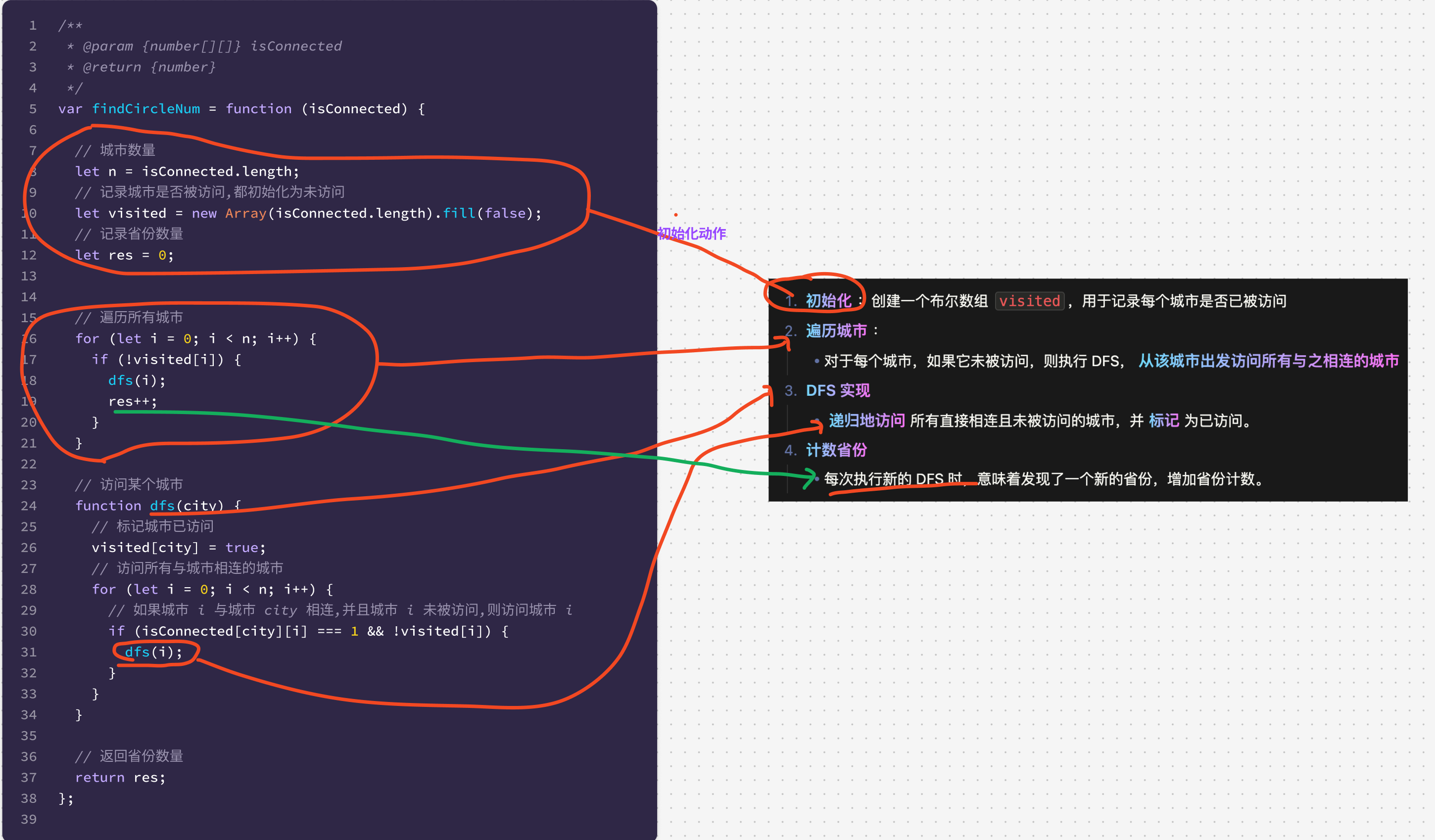
2.2. 源码
/**
* @param {number[][]} isConnected
* @return {number}
*/
var findCircleNum = function (isConnected) {
// 城市数量
let n = isConnected.length;
// 记录城市是否被访问,都初始化为未访问
let visited = new Array(isConnected.length).fill(false);
// 记录省份数量
let res = 0;
// 访问某个城市
function dfs(city) {
// 标记城市已访问
visited[city] = true;
// 访问所有与城市相连的城市
for (let i = 0; i < n; i++) {
// 如果城市 i 与城市 city 相连,并且城市 i 未被访问,则访问城市 i
if (isConnected[city][i] === 1 && !visited[i]) {
dfs(i);
}
}
}
// 遍历所有城市
for (let i = 0; i < n; i++) {
if (!visited[i]) {
dfs(i);
res++;
}
}
// 返回省份数量
return res;
};
2.3. 时间复杂度:O(n^2)
- 外层循环遍历所有城市,最多执行 n 次(n 为城市数量)。
- 对于每个未访问的城市,我们调用 dfs 函数。
- 在 dfs 函数中,我们遍历该城市与所有其他城市的连接关系,这需要 O(n) 的时间。
- 虽然看起来我们可能会多次调用 dfs,但由于 visited 数组的存在,每个城市实际上只会被访问一次。
- 因此,总的时间复杂度是
O(n) * O(n) = O(n^2),因为我们本质上是==遍历了整个 n x n 的邻接矩阵==。
2.4. 空间复杂度:O(n)
- visited 数组:使用了一个大小为 n 的布尔数组来记录每个城市的访问状态,占用
O(n)的空间。 - 递归调用栈:在最坏情况下(所有城市形成一条链),递归调用栈的深度可能达到 n,占用 O(n) 的空间。
- 其他变量(如 n, res)占用常数空间。
- 因此,总的空间复杂度是 O(n)。
2.5. 总结
- 时间复杂度:O(n^2)
- 空间复杂度:O(n)
这个实现的时间复杂度主要来自于需要检查每对城市之间的连接关系。空间复杂度则主要由 visited 数组和可能的递归调用栈深度决定。
虽然这个解决方案在时间复杂度上不是最优的,但它直观且易于理解。对于中小规模的输入,这种方法通常表现良好。如果需要处理非常大规模的数据,可能需要考虑使用**并查集(Union-Find)**等更高效的数据结构来优化性能。
3. 思路二:并查集(Union-Find)
后面讲,先忽略