基础数据结构
#算法/数据结构 #2023/07/30
目录
一、数据结构的分类
数据结构可以从逻辑结构和物理结构两个维度进行分类
(一)线性与非线性:按组成数据元素之前的逻辑结构关系分类
即:数据元素之间的逻辑关系是线性的或者非线性的, 如
- 数组与链表 是
线性的 - 树,体现祖先与后代之间的派生关系,是
非线性的 - 图,由节点和边构成,反映了复杂的网络关系,也是
非线性的
具体分类如下图:
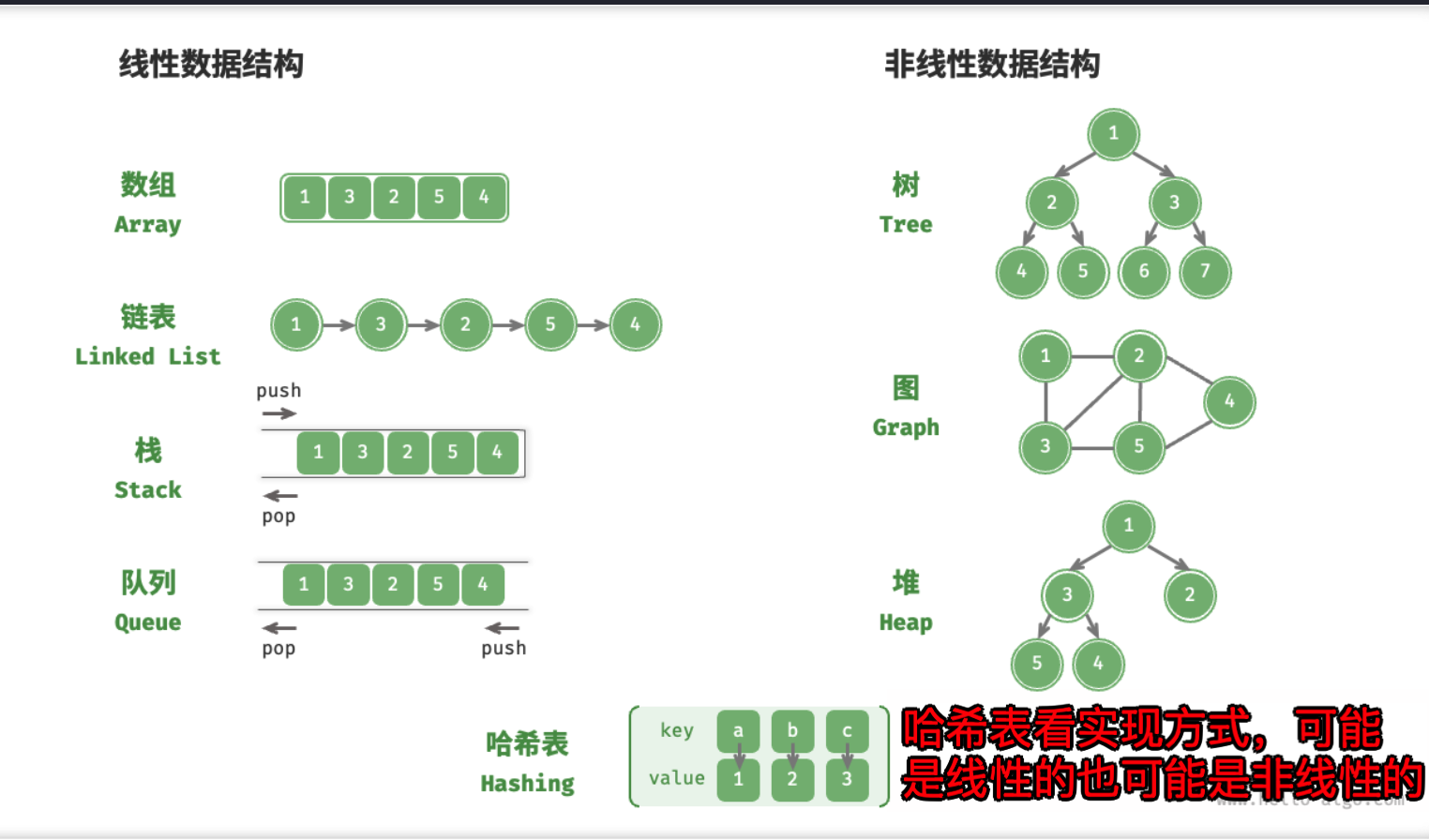
非线性数据结构可以进一步被划分为 树形结构 和 网状结构。
总结:按逻辑结构分类:线性与非线性
- 线性结构 :数组、链表、队列、栈、哈希表,元素存在
**一对一**的顺序关系。- 非线性结构:
- 树形结构 :树、堆、哈希表,元素存在
**一对多**的关系。- 网状结构 :图,元素存在
**多对多**的关系。
(二)连续与离散:按物理结构分类
在数据结构与算法的设计中,算法所占用的**内存峰值**不应超过 **系统剩余空闲内存**;所以如果运行的程序很多并且缺少大量连续的内存空间,那么所选用的数据结构必须能够存储在离散的内存空间内。相反,可以存储到**连续的内存空间**
「物理结构」 反映了数据在计算机内存中的存储方式 ,如下图:
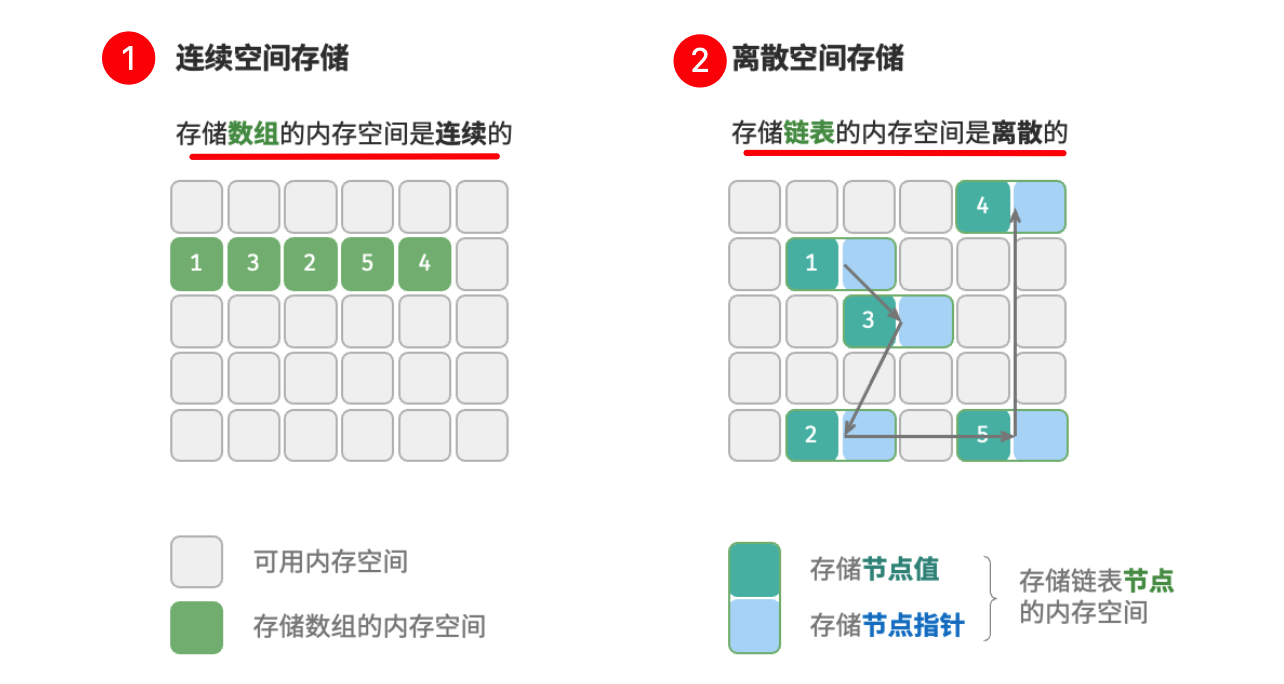
注意上图中的
节点指针与节点值
所有数据结构都是基于数组、链表或二者的组合实现的
- 基于
数组可实现 :栈、队列、哈希表、树、堆、图、矩阵、张量(维度的数组)等- 基于
链表可实现 :栈、队列、哈希表、树、堆、图等。
按照数据结构在初始化后,是否可对其长度进行调整,又可以分为:
- 静态数据结构,即 基于数组实现的数据结构
- 动态数据结构,即 基于链表实现的数据结构
二、基本数据类型
基本数据类型提供了数据的 内容类型,而 数据结构 提供了数据的 组织方式,如:
// JavaScript 的数组数据结构 可以自由存储各种 【基本数据类型】 和 对象
const array = [0, 0.0, 'a', false];
基本数据类型是 CPU 可以直接进行运算的类型,在算法中直接被使用,下表列举了**各种基本数据类型**** **的占用空间、取值范围和默认值
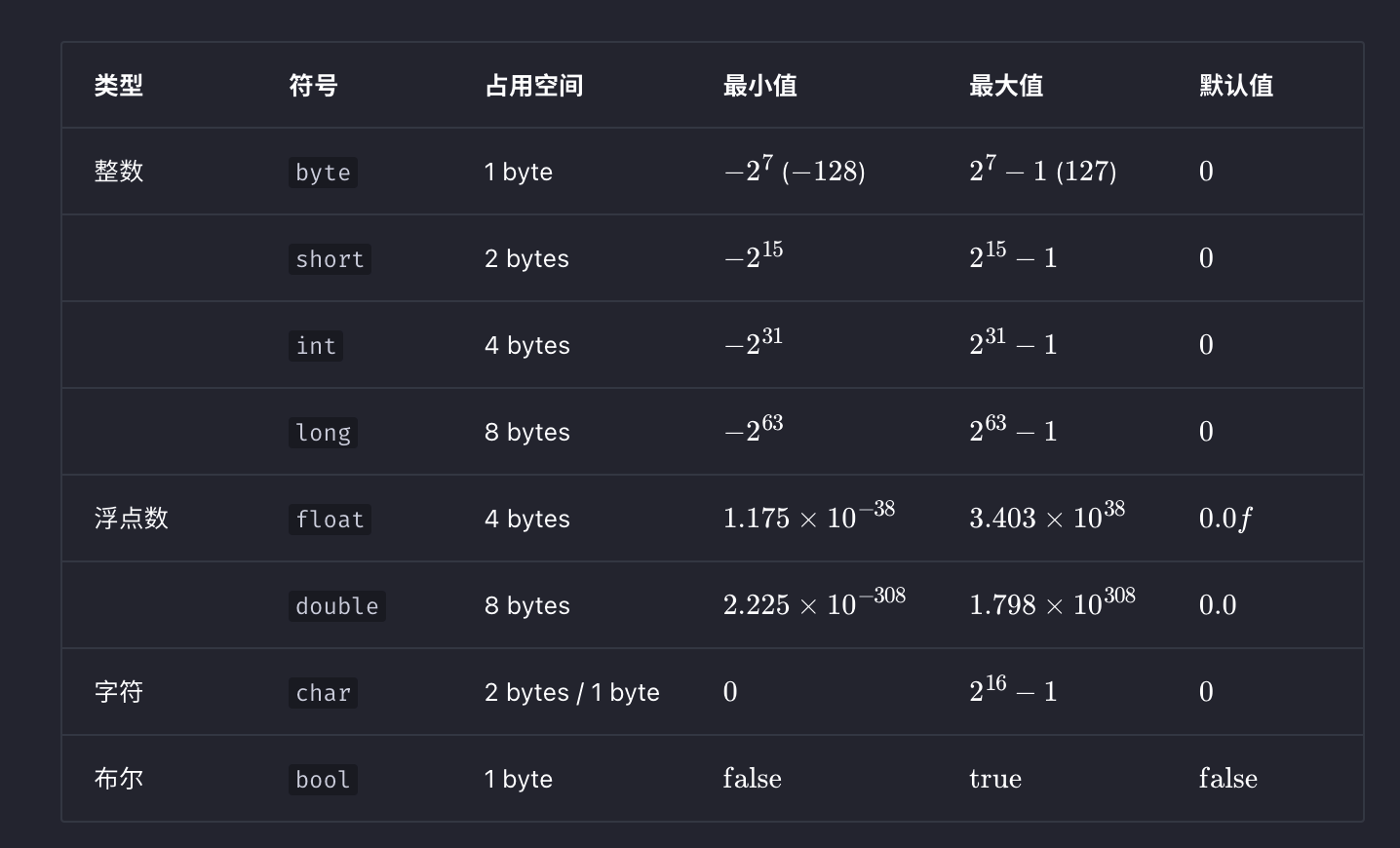
1、现代计算机 CPU 通常将
1 字节作为最小寻址内存单元。因此,即使表示布尔量仅需 1 位(0 或 1 ), 它在内存中通常被存储为 1 字节。2、
1 bytes = 8 bits, 可以表示2^8个不同的数字
三、数字编码
1 byte的取值范围是[-128,127]为什么不是[-128,128]? 它 内在原因涉及到原码、反码、补码的相关知识
(一)原码、反码、补码
- 原码:
- 最高位:视为
符号位,其中0表示正数,1表示负数 - 其余位:表示数字的
- 最高位:视为
- 反码:
**正数**** **的反码与其原码相同**负数**** **的反码是对其原码除符号位外的所有位取反。
- 补码:
**正数**的补码与其原码相同**负数**的补码是在其反码的基础上加1
以上总结就是,如下图:
- 正数的原码、反码、补码相同
- 负数的原码、反码、补码需要转化
- 反码:除符号位外的所有位
取反 - 补码:反码的基础上加
1
- 反码:除符号位外的所有位

原码 最直观,但数字以补码存到计算机中,为什么呢?这是因为原码的 2 个局限性
1、 负数的原码不能直接用于运算,如 1 + (-2) 不应该等于 -1 吗 ?但使用原码计算为 -3


2、数字零 的原码有 +0 和 -0 两种表示方式 , 即 正 0 和 负 0 的原码不同,但补码相同
(二)为什么是 [-128,127] ,128 的特殊性
这里,再来回答 1 byte 的取值范围是 [-128,127] 为什么不是 [-127,127]?
因为, [-127,127] 区间内,所有整数的源码,反码、及补码都可以相互转化,但是 -128 的补码是 1000 0000 ,与 +0 的补码相同,所以计算机规定 补码1000 0000 没有原码,它代表 -128
总之,-128的补码比较特殊,和 +0 冲突了,计算机做特殊处理。
(三)计算机所有运算都是加法
计算机内部的硬件电路主要是基于加法运算设计的。这是因为加法运算相对于其他运算(比如乘法、除法和减法)来说,硬件实现起来更简单,更容易进行并行化处理,从而提高运算速度;如:
- 减法:如
a - b其实就是a + (-b) - 乘法和除法:可以转换为计算多次加法或减法
(四)计算机使用补码的原因
我们可以总结出计算机使用补码的原因:基于补码表示,计算机可以用同样的电路和操作来处理正数和负数的加法,不需要设计特殊的硬件电路来处理减法,并且无需特别处理正负零的歧义问题。这大大简化了硬件设计,并提高了运算效率。
(五)浮点数编码:float 与 double
一个违反直觉的事情:int 和 float 长度相同,都是 4 bytes,但 为什么 float 的取值范围远大于 int ? 这非常反直觉,因为按理说 float 需要表示小数,取值范围应该变小才对
简单来说就是,float 采用了不同的表示方式。如下
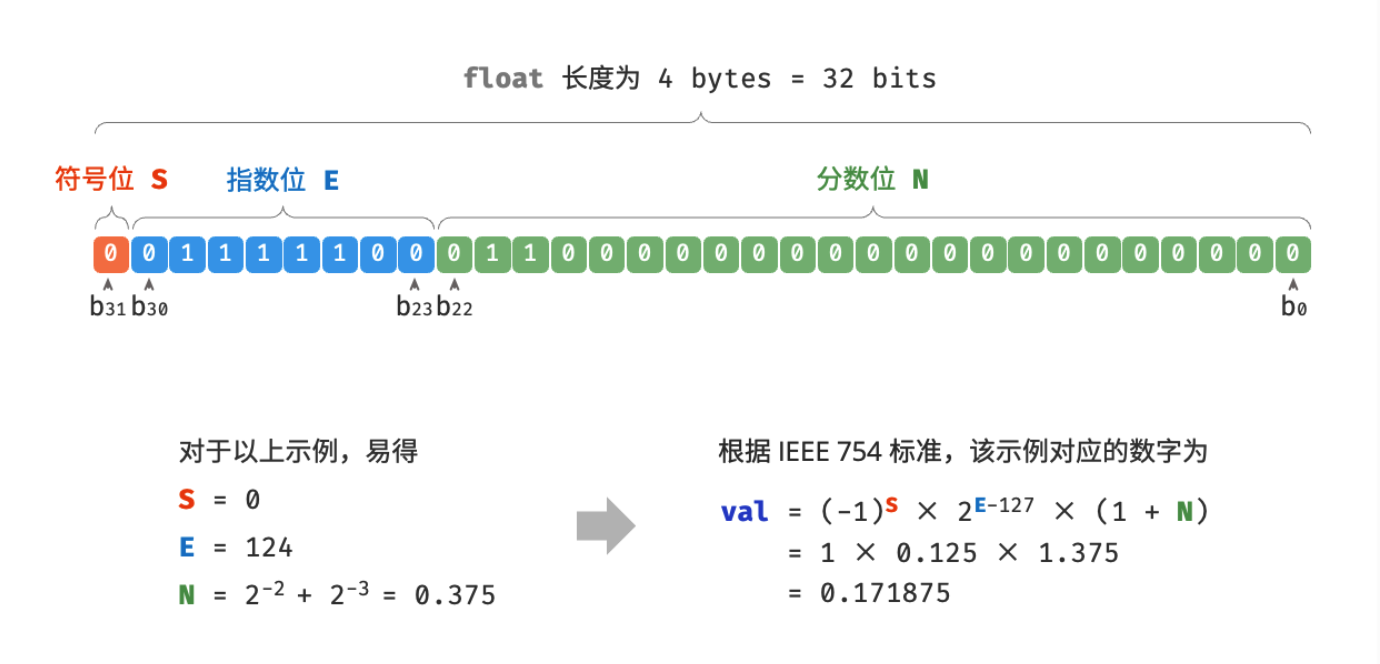
具体的不必展开了,真有需要可以参考 https://www.hello-algo.com/chapter_data_structure/number_encoding/#332
[!info] 1、尽管浮点数
float扩展了取值范围,但其副作用是牺牲了精度 2、双精度double也采用类似float的表示方法,具体的需要再去查吧,这里点到即可
四、字符编码
(一)ASCII 字符集
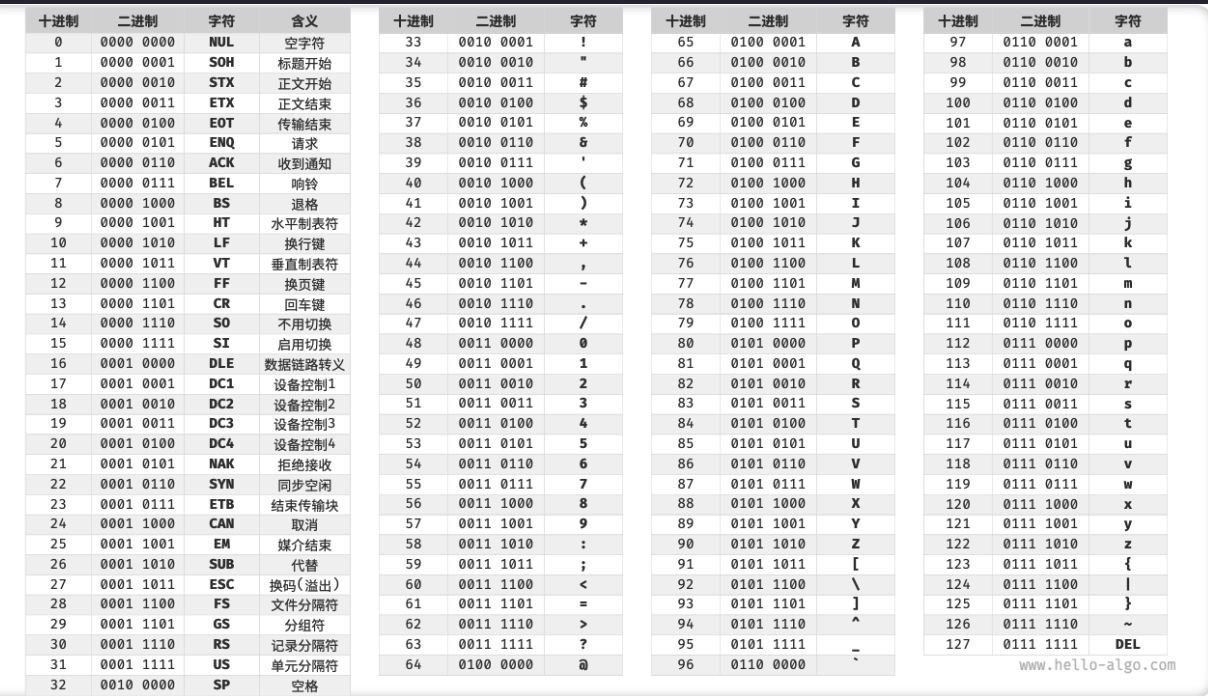
「ASCII 码」是最早出现的字符集,全称为“美国标准信息交换代码” ,采用 7 位二进制 ,所以最多能够表示 128 个不同的字符 ,如下图
(二)GBK 字符集
- 汉字大约有近十万个
GB2312无法处理部分的罕见字和繁体字,所以扩展得到了 GBK 字符集- ASCII 字符使用
一个字节表示,汉字使用两个字节表示。
(三)Unicode 字符集、UTF-8/16/32 编码
1、为何需要 Unicode 字符集?
如果推出一个足够完整的字符集,将世界范围内的所有语言和符号都收录其中,不就可以解决跨语言环境和乱码问题了吗?
2、UTF-8/16/32 编码
- UTF-8 已成为国际上使用最广泛的
Unicode 编码方法。它是一种可变长的编码 - 除了
UTF-8之外,常见的编码方式还包括UTF-16和UTF-32 UTF-16编码:使用 2 或 4 个字节来表示一个字符UTF-32编码:每个字符都使用 4 个字节- 从存储空间的角度看
- 使用
UTF-8表示英文字符非常高效,因为它仅需 1 个字节 - 使用
UTF-16编码某些非英文字符(例如中文)会更加高效,因为它只需要 2 个字节,而 UTF-8 可能需要 3 个字节
- 使用
- 从兼容性的角度看,
UTF-8的通用性最佳,所以许多工具和库都优先支持UTF-8
3、各语言使用的编码情况
- Java 的
String 类型使用UTF-16 编码,每个字符占用 2 字节 - JavaScript 和 TypeScript 的字符串使用
UTF-16 编码的原因与 Java 类似 - C# 使用
UTF-16 编码 - Python 3 使用一种灵活的字符串表示 , 如 对于全部是 ASCII 字符的字符串,每个字符占用 1 个字节
- Go 语言的 string 类型在内部使用 UTF-8 编码。Go 语言还提供了 rune 类型,它用于表示单个 Unicode 码点。
- Rust 语言的 str 和 String 类型在内部使用 UTF-8 编码,Rust 也提供了 char 类型,用于表示单个 Unicode 码点。
4、文件存储或网络传输场景中
字符串在编程语言中的存储方式 和 在文件中存储或在网络中传输 是两个不同的问题。在文件存储或网络传输中,我们一般会将字符串编码为 UTF-8 格式,以达到最优的兼容性和空间效率。
最后:QA
1、为什么哈希表同时包含线性数据结构和非线性数据结构?
哈希表可能同时包含线性(数组、链表)和非线性(树)数据结构,比如 拉链法?
2、char 类型的长度是 1 byte 吗?
跟具体编程语言有关,比如 Java, JS, TS, C# 都采用 UTF-16 编码(保存 Unicode 码点),因此 char 类型的长度为 2 bytes 。
3、为什么出现了不同的编码字符编码,比如 ascii utf8/16/32 等 ?
能表示更多字符 和 存储成本 的 平衡;
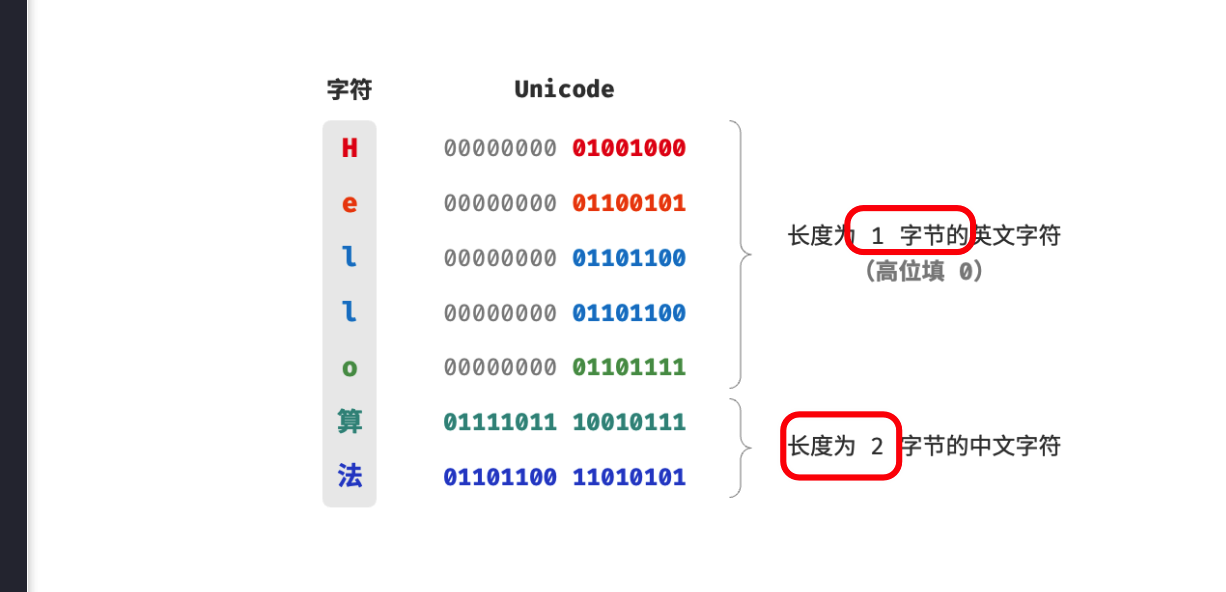
4、如何 UTF-8 是一种可变长的编码? 见下图:
- 对于长度为
1字节的字符,将最高位设置为 0 、其余 7 位设置为 Unicode 码点,即向下兼容了 ascii 码 - 剩余的对于长度为
n字节的字符,如下: - 所以说 Unicode 是一种字符集标准,本质上是给每个字符分配一个编号(称为“码点”),但 它并没有规定在计算机中如何存储这些字符码点

5、UTF-32 编码:每个字符都使用 4 个字节,虽然占空间,但很好理解,如下图
上图只是表达这种编码方式都有 等长字节